Этот блог посвящен обзору алгоритма K-NN, выбору значения k, особенностям алгоритма K-NN, случаям сбоев, компромиссу смещения и дисперсии, влиянию выбросов и плюсам.
Что такое классификация в машинном обучении
Допустим, вы живете в закрытом жилом комплексе, и в вашем обществе есть отдельные урны для разных типов отходов: один для бумажных отходов, один для пластиковых отходов и так далее. По сути, вы здесь классифицируете отходы по разным категориям. Итак, классификация - это процесс присвоения «метки класса» определенному элементу. В приведенном выше примере мы присваиваем ярлыки «бумага», «металл», «пластик» и т. Д. Различным типам отходов.

Алгоритмы классификации в машинном обучении
Теперь, когда мы знаем, что такое классификация, мы рассмотрим алгоритмы классификации в машинном обучении:
- K-Ближайшие соседи (KNN)
- Логистическая регрессия
- Линейная регрессия
В этом блоге мы сосредоточимся только на K-NN. Мы рассмотрим только обзорное понимание этого алгоритма.
Матричная запись
Матрица - это способ организации данных в столбцы и строки. В скобках [] пишется матрица.
Матрица, изображенная ниже, состоит из двух строк и трех столбцов.
- Его размеры - 2 × 3.
- 2 ряда и 3 столбца
- Элементы матрицы ниже: 2, -5, 10, -4, 19, 4.
- Здесь каждая строка представляет точку данных.
- Все столбцы представляют особенности набора данных.

Алгоритм KNN и его интуиция
Шаг 1 - На первом этапе KNN мы должны загрузить обучающие, а также тестовые данные.
Шаг 2. Затем нам нужно выбрать значение K, т. е. ближайшие точки данных. K может быть любым целым числом.
Шаг 3. Для каждой точки в тестовых данных выполните следующие действия:
- 3.1. Рассчитайте расстояние между тестовыми данными и каждой строкой обучающих данных с помощью любого метода, а именно: Евклидова, Манхэттенского или Хэммингового расстояния. Наиболее часто используемый метод расчета расстояния - евклидов.
- 3.2. Теперь отсортируйте их по значению расстояния по возрастанию.
- 3.3 - Затем он выберет верхние K строк из отсортированного массива.
- 3.4. Теперь тестовой точке будет назначен класс на основе наиболее частого класса этих строк.

Поиск наилучшего значения K в K-NN
- Мы используем график ошибок или график точности данных проверки, чтобы найти наиболее подходящее значение K.
- Из графика мы берем K-значение, при котором ошибка является наименьшей, в этом случае K-значение составляет прибл. 9 (из графика ниже).

Особенности KNN
- Алгоритм K Nearest Neighbor широко используется для тестирования более сложных алгоритмов, таких как Deep Networks, SVM, CNN.
- KNN - типичный пример ленивого ученика. Он называется ленивым не из-за его кажущейся простоты, а потому, что он не изучает никаких функций из обучающих данных, а вместо этого запоминает обучающий набор данных. (На самом деле, у KNN нет никаких границ принятия решений, это только для нашего понимания.)
- Мы можем выполнять как регрессию, так и классификацию, используя KNN.
- Это непараметрический метод, означающий, что он не предполагает какого-либо предварительного распределения данных.
- Мы часто выбираем K как нечетное, когда данные имеют четное количество классов, и k как четное, когда данные имеют нечетное количество классов.
- Мы в основном используем евклидово расстояние для данных меньшего размера.
Случаи выхода из строя KNN


- Как показано на рис. 1., если точка запроса находится очень далеко от ближайших соседей, она будет классифицировать точку запроса в неправильный класс.
- Если данные беспорядочно разбросаны или распределены случайным образом, мы получим неверный вывод для точки запроса.
Влияние на KNN несбалансированных данных
На него влияет проблема дисбаланса классов, то есть он пытается классифицировать каждую точку запроса как класс большинства. Но мы можем сбалансировать данные, используя такие методы, как передискретизация и недостаточная выборка.
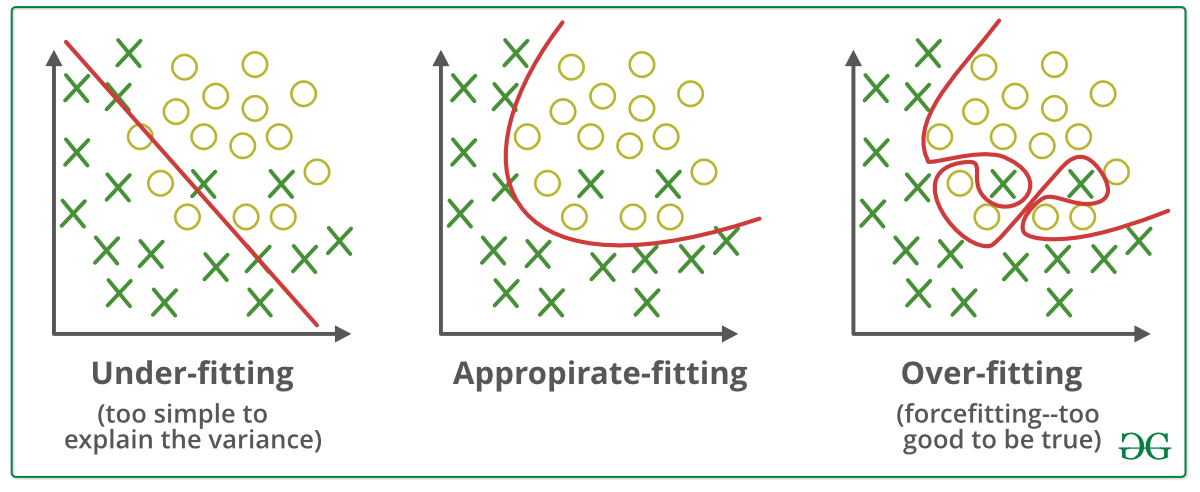
Переоснащение и недостаточное соответствие (компромисс смещения и дисперсии)
Малое значение k может привести к переобучению, а большое значение k может привести к недоподборке.
- Переобучение означает, что модель хорошо работает с данными обучения, но имеет низкую производительность при поступлении новых данных.
- Недообучение относится к модели, которая не подходит для обучающих данных, а также не может быть обобщена для прогнозирования новых данных.
Преимущества
- Отсутствие периода обучения и простота внедрения
- Новые данные могут быть добавлены в любое время, и это не повлияет на модель, так как период обучения отсутствует.
- Хорошо работает с мультиклассовыми задачами
Недостатки
- Чувствительность к зашумленным и отсутствующим данным
- Масштабирование функции должно быть выполнено.
- Не могу получить важность функции.
Ссылки:
Google картинки
Это моя первая статья на Medium, пожалуйста, оставляйте свои комментарии, если вы считаете, что эта статья была для вас полезной. Спасибо за прочтение.