Практические принципы разработки программного обеспечения для мастерства машинного обучения

Почему мы должны заботиться о чистом коде машинного обучения (CMLC)?
Ознакомьтесь с моей последней (в работе) книгой по этой теме с примерами кода, подробными обсуждениями и многим другим! Https://leanpub.com/cleanmachinelearningcode
В конце концов, конвейеры машинного обучения (ML) - это конвейеры программного обеспечения. Они полны ненужных сложностей и повторений. Это смешано с плотной непрозрачностью, жесткостью и вязкостью дизайна. Из-за этих проблем сбои машинного обучения становятся все важнее беспрецедентными темпами. Мы видели, как беспилотные автомобили наезжают на пешеходов в Аризоне. Мы узнали о гендерной предвзятости крупномасштабной системы перевода. Мы видели, как простые маски взламывают системы распознавания лиц в смартфонах. Мы слышали о других «умных» системах, принимающих неверные решения (например, Knight Capital). Пришло время поговорить подробнее о нашей ответственности в области машинного обучения.
Как глобальное сообщество специалистов по науке о данных, автономные системы, которые мы создаем, могут быть дорогостоящими, опасными и даже смертельными. Проблема усугубляется неопытной рабочей силой этого ремесла, которому от 5 до 10 лет. По состоянию на 2019 год 40% специалистов по обработке данных в США имеют опыт работы менее 5 лет. Мы, как сообщество, переживаем бум в разработке и использовании машинного обучения. Это похоже на предыдущий бум программной инженерии в начале 2000-х годов. Это расширение проявляется в виде зверинца конструкций, абстракций, фреймворков и рабочих процессов. Это множество проблем интеграции напоминает нам о старых проблемах программного обеспечения. Некоторые из проблем, возникающих в практике разработки программного обеспечения машинного обучения, являются новыми. Но большинство проблем, связанных с программной инженерией, имеют исторический запах. Возвращение к истокам разработки программного обеспечения может помочь в решении сегодняшних проблем машинного обучения.
Следуя по стопам метода чистого кода, мы можем видеть прямые параллели / аналогии. Все программное обеспечение машинного обучения, которое мы создаем, в конце концов, является программным обеспечением. Интересно заменить «программное обеспечение» на «компонент машинного обучения» в исходных принципах. Это дает новый виток старым трюкам.
Итак, во-первых, каковы преимущества чистого кода машинного обучения? Здесь их как минимум двое. Если эти преимущества вас интересуют, продолжайте читать:
1. Чистый код снижает стоимость изменения ваших конвейеров машинного обучения.
2. Чистый код увеличивает оптимальную реакцию на изменение конвейеров машинного обучения.

Читатели, знакомые с книгами «Чистый код / архитектура», заметят одну вещь. Я экстраполирую эти тексты. Это сделано для того, чтобы выявить сквозные проблемы машинного обучения и традиционной разработки программного обеспечения. Пожалуйста, купите книги, чтобы поддержать первоначального автора. Теперь, когда мы разобрались с этим, мы переходим к основным «адаптированным» принципам чистого кода машинного обучения.
Принципы и вафли

На самом деле нам не нужны принципы, правила, ограничения и вафельницы. Ну, может, вафельницы. Но следующие несколько пунктов - это абстрактные принципы, которые мы можем использовать для продвижения чистого кода. Иногда эти методы могут показаться слишком экстремальными. Тем не менее, их легче понять, чем конвейер модели с несколькими авторами. Добавьте к этому 5 разных членов команды, каждый из которых включил по 10 предположений. Давайте посмотрим, что это за принципы на уровне компонентов и как они могут помочь в практике.
1. Ослабленное соединение

Два компонента машинного обучения связаны, если хотя бы один из них использует другой. Чем меньше эти компоненты ML знают друг о друге, тем слабее они связаны. Компонент ML, который слабо связан с окружающей средой, легче изменить или заменить, чем сильно связанный компонент.
2. Высокая сплоченность
Сплоченность - это степень взаимосвязи элементов машинного обучения в целом. Представьте арахисовое масло и желе. Методы и поля в одном классе машинного обучения, а также классы компонента машинного обучения должны иметь высокую степень согласованности. Высокая согласованность классов машинного обучения и компонентов машинного обучения приводит к более простой и понятной структуре и дизайну кода машинного обучения. Это похоже на принцип единой ответственности, но на уровне компонентов. Вещи, которые меняются по одним и тем же причинам и в одно и то же время, должны быть сгруппированы вместе. Компоненты машинного обучения, которые меняются по разным причинам или в разное время, должны храниться отдельно.
3. Изменения происходят на месте
Программные системы машинного обучения обычно должны поддерживаться, расширяться и изменяться в течение длительного времени. Сохранение изменений на местном уровне снижает сопутствующие затраты и риски для конвейеров машинного обучения. Сохранение локальных изменений компонентов ML означает, что в дизайне есть границы, которые изменения не пересекают.
4. Легко удалить
Обычно мы создаем программное обеспечение для машинного обучения, добавляя, расширяя или изменяя компоненты. Однако удаление элементов машинного обучения важно, чтобы можно было максимально упростить общую конструкцию конвейера машинного обучения. Когда блок ML становится слишком сложным, его необходимо удалить и заменить одним или несколькими более простыми блоками ML.
5. Компоненты разума
Разбейте свою систему машинного обучения на компоненты данных / машинного обучения по размерам, которые вы можете себе представить. Цель состоит в том, чтобы легко предсказать последствия изменений (зависимости, поток управления и т. Д.,…). Классы машинного обучения должны содержать около 100 строк. Методы машинного обучения, такие как методы преобразования, подбора, прогнозирования и прогнозирования, должны содержать не более 15 строк.
Возможность протестировать компонент машинного обучения в ISOLATION - признак хорошей архитектуры. Невозможность протестировать компонент машинного обучения изолированно - признак недобросовестной архитектуры.
Какие принципы разработки программного обеспечения можно использовать для достижения вышеуказанных целей?
Принципы проектирования программного обеспечения SOLID для CMLC
Принципы разработки программного обеспечения SOLID были собраны / уточнены Робертом Мартином, «дядей Бобом», в его прекрасных книгах. Эти принципы служат практическим руководством для инженеров-программистов. Они действуют как строгие рекомендации, применимые как к традиционному программному обеспечению, так и к программному обеспечению для машинного обучения. Давайте посмотрим, что произойдет, когда мы адаптируем их к области машинного обучения, не так ли?

1. Принцип единой ответственности (SRP)

У компонента машинного обучения должна быть одна и только одна причина для изменения.
Чтобы определить, много ли обязанностей у класса / функции, проверьте обслуживаемых им акторов [4]. Предупреждающий знак - это когда есть несколько субъектов, которые могут запросить изменения в этом компоненте. Существует высокая вероятность того, что компонент содержит более чем одну ответственность. Владелец должен разбить этот компонент на более детализированные логические части.

На приведенной выше диаграмме класс MLModel должен измениться из-за множества источников. Здесь у нас есть метод подгонки, схема входных данных и публикация метрики. Этот класс реагирует на изменения в обработке данных, проектировании функций и выборе модели. Владелец должен разделить этот класс на подкомпоненты машинного обучения.
2. Принцип открытости и закрытости (OCP)
Вы должны иметь возможность расширять поведение компонента машинного обучения, не изменяя его.

Например, на этой диаграмме ModelManager запускается с помощью класса SimpleFeaturizer. Однако в версии 2 требовалось использовать SuperFeaturizer. Из-за плотного соединения было невозможно заменить SuperFeaturizer. Для поддержки нового SuperFeaturizer потребуется изменить класс ModelManager.
Это нарушение принципа открытого-закрытого: старый код не должен изменяться для добавления функциональности.
Решение состоит в том, чтобы абстрагироваться от Featurizer в интерфейсном / абстрактном классе. Затем мы заставляем стрелки зависимостей указывать на абстрактные компоненты. После модификации SimpleFeaturizer и SuperFeaturizer являются взаимозаменяемыми. ModelManager может использовать любой из них, не зная внутреннего устройства каждой стратегии. Кроме того, двум Featurizer не нужно знать о ModelManager. Таким образом, разработчик может протестировать их изолированно. В более динамичных языках, таких как Python, нет явной необходимости создавать интерфейс. То есть, если нет строгой проверки типов с использованием метода isinstance. Важная часть - спроектировать взаимодействующие классы так, чтобы они указывали на абстракцию. Сделав ModelManager осведомленным только об интерфейсе, он может использовать любой тип Featurizers. Это позволяет разработчику добавить третий SuperDuperFeaturizer без каких-либо изменений в ModelManager или других подклассах Featurizer. Это верно до тех пор, пока Featurizers реализуют общий интерфейс. ModelManager может игнорировать детали реализации конкретных подклассов. Компоненты жесткого монтажа обычно делают исследование космоса утомительным, вязким и медленным. Это помогает ускорить экспериментальное изменение типов моделей, архитектур и других настроек модели.
Мы хотим сократить количество старого кода ML, который необходимо изменить, чтобы добавить новый код ML. Это достигается путем разделения всего конвейера машинного обучения на компоненты. Затем мы упорядочиваем эти компоненты в ациклические ориентированные графы. Для этого мы заставляем стрелки зависимостей указывать на абстрактные компоненты. Это позволяет нам изолировать компоненты, которые мы хотим защитить от изменений и / или которые более стабильны. Скрытие информации и управление направлением защищают стабильные компоненты машинного обучения. Быстро меняющиеся компоненты машинного обучения также выигрывают от того, что их можно свободно изменять по своему желанию.
3. Принцип замещения Лискова (LSP)
Скоро, пример еще готовлю…
4. Принцип разделения интерфейса (ISP)
Создавайте детализированные интерфейсы компонентов машинного обучения, ориентированные на клиента.
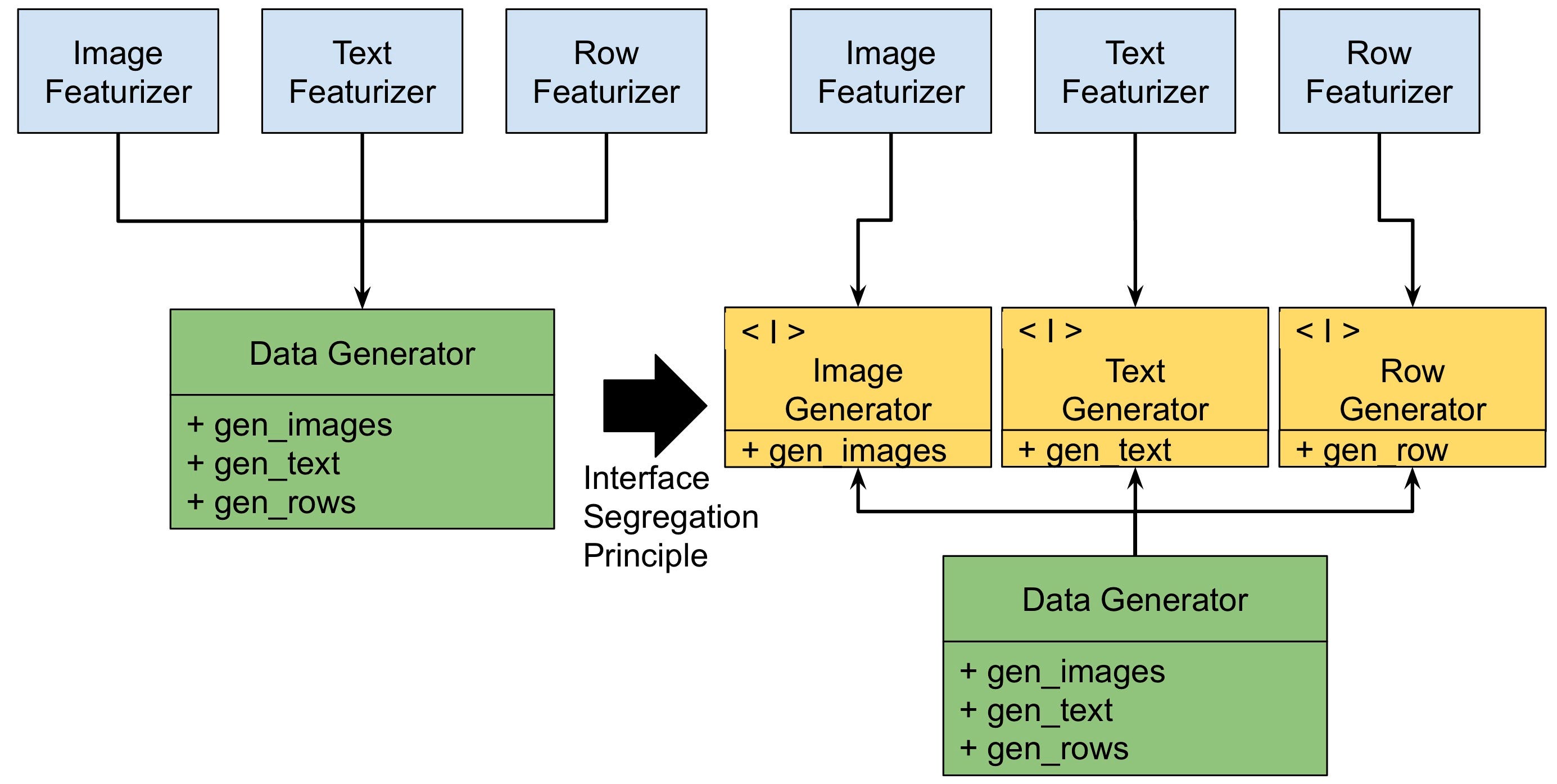
Пример стратегии разделения интерфейса показан на диаграмме выше. Здесь компонент машинного обучения, ImageFeaturizer, зависит от другого компонента DataGenerator для функции gen_images. DataGenerator имеет много других не связанных между собой операций: gen_text и gen_rows.
Проблема в том, что изменение gen_text в компоненте DataGenerator может привести к необходимости изменения компонента ImageFeaturizer.
Это даже если ImageFeaturizer не заботится о gen_text в DataGenerator.
Цель этого принципа - избежать зависимости от компонентов с дополнительным багажом. Эта дополнительная функция может повлиять на пользователей. Пользователям может потребоваться реализовать ненужные функции для совместимости с их зависимостями. Этот принцип советует создавать клиентские интерфейсы. Это считается лучше, чем один большой общий интерфейс для всех клиентов.
5. Принцип инверсии зависимостей и метод внедрения зависимостей
Положитесь на абстракции конвейера машинного обучения, а не на конкреции конвейера машинного обучения.
Стрелки зависимостей должны указывать на стабильные компоненты в конвейере машинного обучения. Если вы ожидаете, что нестабильный компонент будет часто меняться, защитите компоненты, которые должны от него зависеть. В этом помогает инверсия зависимостей метода проектирования элементов управления.
Этот принцип позволяет использовать архитектуру плагинов. Приложение может быть расширено внешними плагинами. Это делается путем создания интерфейсов. Эти интерфейсы изолируют основные компоненты приложения от подключаемых модулей.
Возьмем взаимодействие между классом ModelTrainer и различными библиотеками машинного обучения. Цель ModelTrainer - создать своего рода классификатор. В зависимости от прогнозируемой производительности нам могут потребоваться разные библиотеки. Здесь кандидатами являются Scikit-Learn, Tensorflow и PyTorch.
Основная цель приложения - не «Давайте использовать одну из этих прекрасных библиотек в нашем проекте». Основная цель - создавать модели / приложения, которые приносят пользу пользователям. Библиотеки машинного обучения - это детали, которые не должны мешать работе ядра приложения.

Внедрение зависимостей - это метод для выполнения этой инверсии зависимостей. Это помогает изолировать основное классификационное приложение от подключаемых модулей библиотеки машинного обучения. Во-первых, мы заставляем тренажер моделей зависеть от интерфейса ModelBuilder. Это позволяет ModelTrainer взаимозаменяемо использовать любую реализацию построителя моделей. Однако мы можем пойти дальше. ModelTrainer - это компонент высокого уровня, который не должен знать о проблемах низкого уровня. Эти низкоуровневые проблемы связаны с отдельными реализациями. Чтобы решить эту проблему, мы можем использовать ассемблер. Это «связывает» реализацию построителя моделей с тренером моделей во время выполнения. ModelTrainer может игнорировать конкретный построитель моделей, который использует приложение. Это устраняет зависимость от обучающего модуля модели до реализаций построителя модели.
Влияние на машинное обучение, управляемое тестированием (TDML)
Все эти дизайнерские усилия имеют одно важное преимущество. Вы можете тестировать свои компоненты изолированно. Чем больше тестов мы добавим, тем больше покрытия мы получим для компонентов. Это заставляет разработчиков доверять коду, с которым они взаимодействуют. Это не только зарезервировано для установленных компонентов программной инженерии. Его также можно применить к компонентам машинного обучения.
Ключевым аспектом TDML является то, что его нельзя использовать на заднем плане. Тесты должны быть написаны до кода. Написание тестов после кода - проигранная битва.
Долг технологии машинного обучения
Как это соотносится с принципами чистого кода
Взаимосвязь между технологическим долгом машинного обучения и рекомендациями по чистому кодексу была исследована в [5]. Мы можем сопоставить типичные проблемы конвейеров машинного обучения в больших производственных условиях с концепциями чистого кода, которые мы рассмотрели.

Запутанность возникает из-за того, что данные машинного обучения и код глубоко переплетены. Это приводит к нарушению принципа SRP. Еще одно проявление нарушения SRP - наличие компонентов связующего кода. Они объединяют большой набор частично связанных функций в одну большую взаимосвязанную систему.
Скрытые петли обратной связи возникают, когда развернутые модели изменяют будущие распределения обучения. Модель влияет на действия клиентов. Затем клиенты реагируют, приводя к результатам, отличным от того, что было в прошлом. Фактически, каждое повторное обучение модели с этими новыми данными позволяет ВНЕШНЕМУ источнику изменений НЕПОСРЕДСТВЕННО модифицировать ваше программное обеспечение !. Это явное нарушение принципа открытия-закрытия. Модель потенциально открыта для изменений путем непосредственной адаптации к новым данным. От некоторых видимых петель обратной связи можно защитить итеративное применение OCP, однако некоторые скрытые обратные связи обнаружить труднее. Один из примеров - «агрегированные функции». Еженедельные суммы требуют времени, чтобы адаптироваться к новым данным. Для обработки этого изменения в конвейере ml моделям потребуются новые версии обучающего кода. Если система не соответствует принципу OCP, изменения будут дорогостоящими, и разработчики могут решить отложить их. Эта задержка усиливает петли обратной связи, которые имеют тенденцию к усложнению. Следование принципу OCP может помочь быстрее смягчить эти петли обратной связи.
Незаявленные потребители начинают появляться, когда компонент предоставляет общий интерфейс. Это обеспечивает общий недифференцированный доступ. Руководство ISP поощряет разработчиков создавать клиентские интерфейсы. Этот принцип приводит к более тонким интерфейсам и снижает риск появления незаявленных потребителей.
Трубопроводные джунгли обычно появляются одновременно с проблемой кода Glue. Это показывает, как приложение преобразует / перемещает данные по различным компонентам. Трубопроводы работают на самом низком уровне абстракции. Здесь фактические данные перемещаются и трансформируются, и в итоге мы получаем очень жесткие конкреции. Это означает, что конвейер нельзя изменить, не замучив код. Цель этой пытки - поддержать множество экспериментальных путей кода. Для этого разработчики создают дублированный код и нездоровые зависимости. Принципы OCP и ISP нарушаются, чтобы что-то работало. Разработчики начинают создавать сеть зависимостей, которая противоречит принципу DIP. Зависимости начинают переходить к конкретным реализациям. Отложено проектирование более стабильных / абстрактных классов и конструкций. Эта стратегия сочетает в себе этапы разработки с этапами выбора модели. Обучение модели с публикацией модели. Становится трудно тестировать изолированно. Тестирование этапа проектирования признаков без этапа выбора модели становится сложным. Тестировать публикацию модели без обучения модели становится сложнее. Разработчики могут исправить «трубопроводные джунгли» путем рефакторинга с использованием принципов SRP, ISP, OCP и DIP.
Что нас ждет в будущем, если мы не будем саморегулироваться
Вот вероятный сценарий, если мы не возьмем на себя ответственность за нашу профессию, построив и применяя принципы и передовые методы:
- Постоянная неопытность специалистов по машинному обучению будет только расти по мере того, как все больше и больше новичков в области данных и инженеров присоединяются к системам, которые управляют миллионами жизней и миллиардами долларов, и получают их.
- Один конвейер машинного обучения, где-нибудь, будет смертельным. Дадим всем, кто связан с машинным обучением, плохую репутацию.
- Законодателям придется принять меры против создаваемых нами автоматизированных систем.
- Когда вступят в силу правила машинного обучения, всем нам придется следовать правилам, установленным неспециалистами.
- Нам нужны самостоятельные инструкции по регулированию, и TDML - неплохой вариант.
Я надеюсь, что эта небольшая экскурсия в страну мира Чистого кода помогла. Надеюсь, теперь вы можете использовать это в качестве отправной точки для поддержания высокого уровня мастерства в машинном обучении.
Спасибо за прочтение.
Обратите внимание, что мнения, выраженные в этом посте, являются моими собственными и не обязательно мнениями моего работодателя.
Мы нанимаем! Если вас это интересует, пожалуйста, ознакомьтесь с нашими открытыми вакансиями в Xandr Data Science Platform Engineering: https://xandr.att.jobs/job/new-york/data-science-platform-engineer-python-scikit-learn-tensorflow- keras-adtech-marketplace / 25348/13937710
использованная литература
- Дядя Боб Мартин - Чистый кодер:
Https://www.youtube.com/watch?v=NeXQEJNWO5w
2. Памятка по чистому коду:
Https://www.bbv.ch/images/bbv/pdf/downloads/V2_Clean_Code_V3.pdf
3. Веб-сайт Clean Coders:
4. Роберт Мартин о принципе единственной ответственности:
Https://blog.cleancoder.com/uncle-bob/2014/05/08/SingleReponsibilityPrinciple.html
5. Вдумчивое машинное обучение с Python, книга
6. Пример кода Python от dboyliao: