
Описательная статистика - это исследование анализа данных для содержательного описания, отображения или обобщения данных. Он включает в себя расчет различных показателей, таких как показатель центра, показатель изменчивости, процентили, а также построение таблиц & графики.
В этой статье я расскажу об основных принципах этих общих описательных мер и построении таблиц и графиков. В то же время практические шаги, необходимые для выполнения этих вычислений описательных мер и построения таблиц и графиков, будут продемонстрированы с использованием Pandas и Seaborn. Pandas и Seaborn - это библиотеки Python, которые обычно используются для статистического анализа и визуализации.
Предварительные требования библиотеки Python
- Панды
- Матплолиб
- Сиборн
Примечание.
Настоятельно рекомендуется использовать Jupyter Notebook, чтобы выполнять все задачи по кодированию, описанные в этой статье. Все представленные здесь скрипты Python написаны и протестированы в Jupyter Notebook. Вы можете обратиться к официальному сайту Jupyter для получения дальнейших инструкций по установке Jupyter Notebook на вашем компьютере.
Наборы данных
Мы будем использовать общедоступный набор данных, относящийся к ценам на жилье в Мельбурне, MELBOURNE_HOUSE_PRICES_LESS.csv в качестве примеров данных. Набор данных доступен на Kaggle.
Тема 1: Типы данных
1.1 Числовые и категориальные данные
Перед тем, как начинать какие-либо технические расчеты и работы по построению графиков, очень важно понять, какие данные обычно используются в статистических исследованиях. Существует два основных типа данных: категориальные данные (качественные) и числовые данные (количественные).
- Категориальные данные: нечисловая информация, такая как пол, раса, религия, семейное положение и т. д.
- Числовые данные: измерение или подсчет, например рост, вес, возраст, зарплата, количество детей и т. д.
1.2 Код Python на практике
В статистическом анализе или проекте по науке о данных данные (категориальные, числовые или и то, и другое) часто хранятся в табличном формате (например, в электронной таблице) в файле CSV.
Чтобы лучше понять, давайте начнем с визуализации данных в нашем CSV-файле (MELBOURNE_HOUSE_PRICES_LESS.csv) с помощью библиотеки Pandas.
- Строка 1: Импорт библиотеки Pandas.
- Строка 3: Используйте метод read_csv для считывания необработанных данных из файла CSV во фрейм данных df. фрейм данных - это двумерная структура данных, подобная массиву, для статистических моделей и моделей машинного обучения.
- Строка 4: используйте метод head () фрейма данных, чтобы показать первые пять строк данных.
Когда мы запускаем коды в Jupyter Notebook, вы увидите, что данные представлены в таблице, которая состоит из 13 переменных (столбцов).

Pandas также предлагает другой полезный метод, info (), для получения дополнительных сведений о типе данных для каждой переменной в нашем наборе данных. В том же Jupyter Notebook просто создайте новую ячейку под предыдущими кодами, добавьте следующую строку кода и запустите ее:

Результат показывает всего 63023 записи в наборе данных. Как правило, столбцы, связанные с типом данных «int64» и «float64», обозначают числовые данные, а тип данных «объект» обозначает категориальные данные.
* Единственное исключение - «Почтовый индекс». Хотя почтовый индекс представлен в виде числа (int64), он не обязательно является количественным. Почтовый индекс - это просто числа, применяемые к категориальным данным.
С помощью всего одной строчки кода Pandas позволяет нам идентифицировать наши числовые данные, которые состоят из «Номера», «Цена», «Количество объектов» и «Расстояние. , а остальные - категориальные данные.

Тема 2: Измерение центра

Один из распространенных способов обобщения наших числовых данных - это выявить центральную тенденцию наших данных. Например, мы можем спросить: «Какое наиболее типичное значение цены дома в нашем наборе данных?». Чтобы ответить на этот вопрос, мы можем прибегнуть к двум наиболее распространенным методам измерения центра: среднему и среднему.
2.1 Среднее
Среднее - это среднее значение всех чисел. Для вычисления среднего значения необходимо выполнить следующие действия:
- суммировать все значения целевой переменной в наборе данных
- разделить сумму на количество значений
Например, если у нас есть набор из пяти значений, [70, 60, 85, 80, 92],

Однако иногда среднее значение может вводить в заблуждение и не может эффективно отображать типичное значение в нашем наборе данных. Это связано с тем, что на среднее значение могут влиять выбросы.
Выбросы - это числа, которые являются либо чрезвычайно высокими, либо крайне низкими по сравнению с остальными числами в наборе данных.
Давайте рассмотрим еще два набора данных: [70, 60, 1, 80, 92] и [70, 60, 300, 80, 92].

Значение Mean_1 выше направлено вниз из-за чрезвычайно низкого выброса «1». С другой стороны, Среднее_2 движется вверх из-за чрезвычайно высокого выброса «300».
2.2 Медиана
Медиана - это среднее значение отсортированного списка чисел. Для получения медианы из списка чисел необходимо выполнить следующие действия:
- отсортировать числа от наименьшего к наибольшему
- если в списке нечетное количество значений, значение в средней позиции является медианным
- если в списке есть четное количество значений, среднее из двух значений в середине будет медианой
Ниже приведены два примера, показывающих, как мы можем получить медианное значение из нечетного числа значений и четного числа значений.

Если у нас есть набор из восьми значений, [30, 45, 67, 87, 94, 102, 124],

Примечание. Выбросы не влияют на медианное значение.
Выбор, который мы делаем, использовать среднее или медиану в качестве меры центра, зависит от вопроса, к которому мы обращаемся. Как правило, мы должны указывать как среднее, так и медианное значение в нашем статистическом исследовании и позволять читателям интерпретировать результаты самостоятельно.
2.3 Код Python на практике
Для вычисления среднего и медианного значения Pandas предлагает нам два удобных метода: mean () и median (). Давайте использовать Pandas, чтобы получить среднее и медианное значение цены нашего дома из набора данных.
Строки 1 и 4: df [‘Price’] выберет столбец, в котором будут указаны значения цен. За ним следует точечный синтаксис для вызова методов mean () и median () соответственно.
Строки 2 и 5: выведите среднее значение и медианное значение.
Обратите внимание, что методы Pandas mean и median уже инкапсулируют для нас сложную формулу и вычисления. Все, что нам нужно, - это просто убедиться, что мы выбрали правильный столбец из нашего набора данных и вызываем методы для получения среднего и медианного значения. Результат показан ниже:

Тема 3: Измерение вариации

В наборе данных всегда наблюдается вариация. Очень необычно видеть, что весь набор чисел имеет одни и те же значения, как показано ниже:

При сравнении разницы / изменчивости между двумя наборами данных среднее значение и медиана не подходят для этой цели. Чтобы объяснить это дальше, давайте посмотрим на два примера ниже.

Оба набора данных, приведенные выше, имеют одинаковое среднее и медианное значение, равное 300. Однако у них разный уровень вариации. Числа в первом наборе данных имеют меньшую вариацию, чем во втором, несмотря на то, что оба они имеют одинаковое среднее и медианное значение. Следовательно, нам нужен другой вид измерения, чтобы изучить изменчивость нашего набора данных.
3.1 Стандартное отклонение
Один из распространенных методов измерения вариации нашего набора данных - вычисление стандартного отклонения (SD). SD - это просто измерение, позволяющее определить, как набор значений отклоняется от среднего. Низкое SD показывает, что значения близки к среднему, а высокое SD указывает на сильное отклонение от среднего.
Шаги для расчета SD следующие:
- Вычислить среднее значение набора данных
- Для каждого числа в наборе данных вычтите его со средним значением.
- Возвести в квадрат разницу, полученную на шаге 2.
- Подведите итоги шага 3
- Разделите сумму, полученную на шаге 4, на количество значений в наборе данных минус один.
- Квадратный корень из результата шага 5

Примечание:
- SD должно быть положительным числом
- На SD влияют выбросы, так как его расчет основан на среднем значении.
- Наименьшее возможное значение SD равно нулю. Если SD равно нулю, все числа в наборе данных имеют одно и то же значение.
3.2 Код Python на практике
Pandas также предлагает удобный метод std () для расчета SD. Давайте попробуем использовать метод панд для расчета SD для нашей цены на жилье.
Строка 1: вызовите метод std () для расчета SD цены дома.
Опять же, мы видим, что метод Pandas std () уже инкапсулировал для нас сложное вычисление SD, и мы можем получить значение SD на лету.

Тема 4: Графический способ отображения распределения числовых данных

В приведенных выше разделах рассматриваются два примера описательных показателей (мера центра и мера вариации), с использованием одного значения. В этом разделе мы увидим, как мы можем также изучить распределение данных, используя графический способ.
4.1 Коробчатая диаграмма
Один из подходов к выявлению распределения данных - найти пятизначную сводку из нашего набора данных . Пятизначное резюме включает:
- Минимум
- 25-й процентиль или первый квартиль (Q1)
- Медиана
- 75-й процентиль или третий квартиль (Q3)
- Максимум
Здесь это необходимо для объяснения значения «процентиль».
Процентиль - это мера, используемая в статистике, указывающая значение, ниже которого попадает определенный процент наблюдений в группе наблюдений. Например, 20-й процентиль - это значение, ниже которого можно найти 20% наблюдений . (Источник: Википедия)
Пятизначная сводка предоставляет быстрый способ приблизительно определить минимальный, 25-й процентиль, медиану, 75-й процентиль и максимальное число из нашего набора данных. Один из графических способов представить эту пятизначную сводку - создать коробчатую диаграмму.

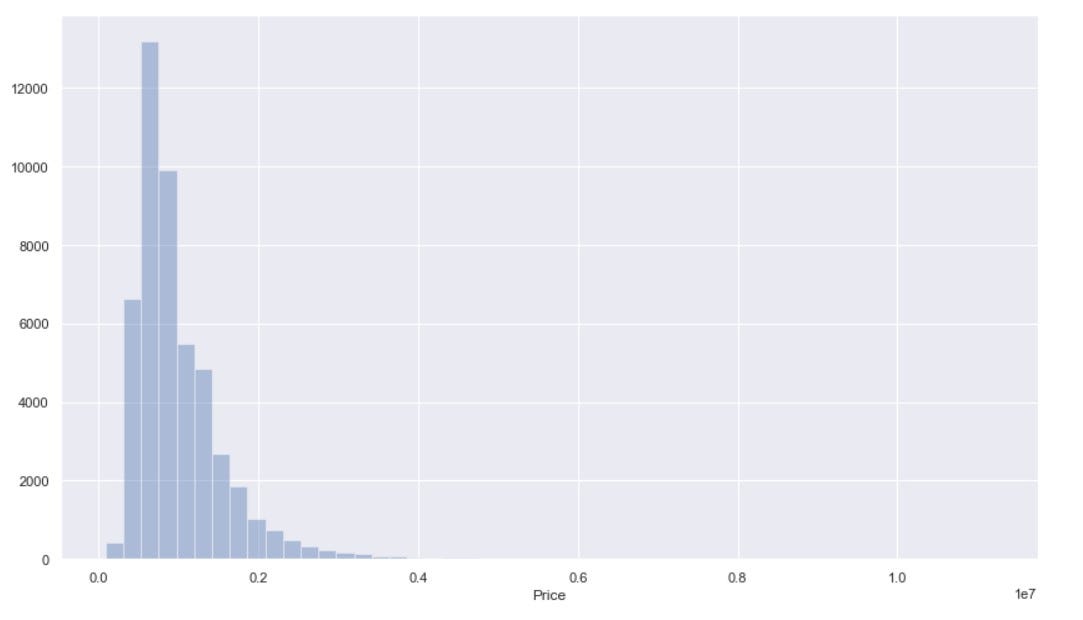
4.2 Гистограмма
Гистограмма - это графический дисплей, в котором используются прямоугольные полосы для отображения частотного распределения набора числовых данных. Гистограмма позволяет нам визуализировать базовый образец распределения наших данных.
Шаги, необходимые для построения гистограммы, следующие:
- Разделите наши данные на интервалы, которые называются ячейками.
- Запишите количество вхождений (частоту) для каждого числа в наборе данных и сведите их в Таблицу частот.
- Постройте гистограмму на основе таблицы частот, полученной на шаге 2.

4.3 Код Python на практике
В этом разделе мы будем использовать библиотеку Seaborn для создания диаграммы и гистограммы для нашей цены на жилье.
Во-первых, давайте начнем с коробчатой диаграммы.
- Строки 1 и 2: импорт библиотеки Matplolib и Seaborn
- Строка 4: волшебная функция, которая позволяет отображать наш график в Jupyter Notebook.
- Строка 6: задайте тему Seaborn.
- Строка 7: установите размер рисунка на графике.
- Строка 8: Используйте метод boxplot () Seaborn для создания коробчатой диаграммы. Мы устанавливаем «Цена» в качестве входных данных для построения данных. Значение «v» в параметре «orient» предназначено для визуализации нашего блочного графика в вертикальном стиле.

Фактически, в нашем наборе данных есть три разных типа домов: «H» - дом, «U» - дом и «T» - таунхаус. Мы можем создать коробчатый участок для каждого типа дома. Для этого нам просто нужно добавить еще один параметр «y» в наш метод Seaborn boxplot ().
- Строка 1: установите «Тип» как данные по оси X и «Цена» как данные по оси Y.

Теперь давайте попробуем построить гистограмму, чтобы наблюдать за распределением данных по нашим данным о ценах на жилье. Мы будем использовать Seaborn distplot () для создания нашей гистограммы.
- Строка 1: Это необходимый шаг для использования метода dropna () для удаления всех нулевых значений из столбца «Цена» в нашем наборе данных о жилье. Seaborn не сможет создать гистограмму, если в столбце есть какое-либо нулевое значение.
- Строка 2. Задайте размер рисунка графика гистограммы.
- Строка 3: используйте метод distplot () для создания гистограммы. Есть только один требуемый ввод - это отфильтрованные данные о ценах на жилье (без нулевых значений).
Тема 5: Исследование категориальных данных

В предыдущих разделах мы рассмотрели только описательный статистический анализ числовых данных (цены на жилье). Как насчет категориальных данных? На наш взгляд, у нас могут возникнуть некоторые вопросы, относящиеся к категориальным данным в нашем наборе данных по жилью:
- Какова доля каждого типа домов (h - дом, t - таунхаус и u - квартира) в нашем наборе данных?
- В каком регионе больше всего продаж недвижимости?
На первый вопрос можно ответить, нарисовав круговую диаграмму, тогда как столбчатая диаграмма может быть хорошим вариантом ответа на второй вопрос.
5.1 Круговая диаграмма
Круговая диаграмма - это простой графический способ показать числовую долю категориальных данных в наборе данных. Круговая диаграмма также известна как круговая диаграмма (Источник: Википедия), которая разделена на части в форме клина. . Длина дуги каждой части пропорциональна относительной частоте категориальных данных.
Давайте посмотрим на один пример круговой диаграммы.

Взгляд на приведенную выше круговую диаграмму должен мгновенно дать нам представление о показателях продаж за год. Очевидно, что более половины продаж приходится на 1-й квартал, в то время как 4-й квартал показывает самые низкие продажи.
5.2 Гистограмма
Гистограмма - еще одно эффективное графическое отображение категориальных данных. Гистограмма - это графический дисплей, на котором с помощью столбцов отображается количество вхождений или частота появления каждой категории данных.
Опять же, давайте посмотрим на один пример гистограммы.

5.3 Код Python на практике
Pandas предлагает функцию построения круговой диаграммы, чтобы показать долю каждого типа дома в нашем наборе данных.
- Строка 1: Используйте метод Pandas «value_counts ()», чтобы получить частоту для каждого типа дома.
- Строка 2–4. Создайте новый фрейм данных, df2. В этом новом фрейме данных есть только один столбец «house_type» для хранения счетного числа каждого типа дома, «type_counts»
- Строка 5: присвойте имя столбца «house_type» параметру «y». Это позволяет методу Pandas pie () автоматически создавать круговую диаграмму на основе количества домов каждого типа. Параметр «autopct» включен для отображения процентного содержания каждого типа дома на круговой диаграмме.

С помощью круговой диаграммы мы можем легко определить процентную разбивку для каждого типа дома.
Затем мы можем использовать Seaborn для создания гистограммы, чтобы показать количество продаж недвижимости по регионам.
- Строка 1–2: установите для темы Seaborn значение «darkgrid» и установите размер рисунка графика.
- Строка 3: Назначьте категориальную переменную «Regionname» параметру «x». Назначьте набор данных для построения графика «df» параметру «data». Метод Seaborn «countplot ()» автоматически фиксирует количество вхождений каждого региона и отображает гистограмму.

Из столбчатой диаграммы выше мы можем сделать вывод, что у Южного Метрополита самое большое количество продаж недвижимости.
Выводы
Эта статья представляет собой краткое руководство по описательной статистике, в которой представлены несколько основных описательных показателей и графических дисплеев, которые широко используются сообществом. Основная цель - просто показать некоторые возможные способы осмысленного обобщения нашего набора данных с помощью Pandas и Seaborn. Pandas и Seaborn должны быть двумя основными инструментами для тех, кто хочет участвовать в проектах по статистическому анализу или науке о данных. Одним из основных преимуществ Pandas и Seaborn является то, что они уже инкапсулировали множество сложных вычислений и построили шаги в несколько строк скриптов Python. Это позволяет упростить процесс анализа данных и сэкономить время.
Тем не менее, затронутые здесь темы не являются исчерпывающими, и есть много других тем, которые здесь не обсуждаются. Кроме того, существующие темы, представленные в этой статье, также можно разбить и обсудить с более подробной информацией (для чего может потребоваться еще несколько статей, посвященных каждой конкретной теме).
Я бы хотел, чтобы эта статья могла дать толчок и общий обзор описательной статистики. Надеюсь, вам понравится читать.
Ресурсы Github:
Все представленные здесь скрипты Python написаны в Jupyter Notebook и доступны через репозиторий Github. Не стесняйтесь загрузить блокнот с сайта https://github.com/teobeeguan2016/Descriptive_Statistic_Basic.git
использованная литература
- Определение процентиля (взято с https://en.wikipedia.org/wiki/Percentile)
- Определение круговой диаграммы (взято с https://en.wikipedia.org/wiki/Pie_chart)