
В этом проекте я хочу попрактиковаться в Обработке естественного языка (NLP) и Неконтролируемом машинном обучении. После некоторого исследования того, какой набор данных я мог получить из Интернета, я нашел набор данных о женской одежде реального бизнеса электронной коммерции. Я думаю, что было бы здорово и полезно для бизнеса, если бы я мог разработать автоматизацию для бизнеса, чтобы извлекать идеи из их обзоров одежды. Потому что читать тысячи отзывов непросто, и это трудоемкая задача.
Это могло быть полезно по разным причинам. Например:
- Понимать тенденции: понимать, о чем люди говорят, о вещах, которые им нравятся, или о вещах, которые им не нравятся.
- Улучшайте свои продукты на основе отзывов пользователей.
- Чтобы узнать у пользователя о продукте, который ему не нравится, и разобраться в проблеме.
- Чтобы снизить процент возврата, сборы за пополнение запасов - одна из больших статей расходов для электронной коммерции, чтобы преуспеть или даже остаться в живых.
Выше приведены лишь несколько вещей, которые вы можете сделать с отзывами клиентов.
Проблемы, которые я хочу решить
Итак, в рамках этого проекта я хочу изучить следующее:
- Тематическое моделирование: например, какие положительные и отрицательные вещи люди говорят об этой одежде / обуви. Чтобы узнать, смогу ли я найти какую-либо тему, вычислив частоты встречаемости слова или сочетания слов в теме.
- Разделение хороших и плохих обзоров с помощью кластеризации: для разделения или выявления закономерностей плохих и хороших отзывов для разных продуктов, чтобы можно было отправить их в соответствующие отделы для внимания с помощью методов кластеризации. Это может быть очень сложно, поскольку метод кластеризации - это метод неконтролируемого машинного обучения, который находит скрытые закономерности в данных.
Дизайн проекта
- Очистить и выполнить Исследовательский анализ данных (EDA) на моих данных.
- Векторизация моих очищенных текстовых данных (Count Vectorizer и TF-IDF).
- Создайте WordCloud, чтобы узнать, какие слова чаще всего говорят люди.
- Предварительно сформируйте тематические модели, чтобы увидеть, смогу ли я найти несколько четких различных тем, о которых говорят люди.
- Используйте методы кластеризации, чтобы сгруппировать шаблон из моих текстовых данных и посмотреть, смогу ли я сгруппировать эти плохие отзывы (или отдельные типы обзоров). И использовать TSNE для визуализации моих кластеров.
- Наконец, выполните задачу контролируемого обучения с помощью столбца Рейтинг из набора данных, чтобы классифицировать хорошие и плохие отзывы.
Данные и технологии, которые я использовал
Набор данных, который я использовал, мог быть получен из Kaggle, он состоит из 23486 записей обзоров различной одежды и 11 различных столбцов.

В этом проекте я использовал следующие инструменты: numpy, pandas, matplotlib, seaborn, wordcloud, sklearn, особенно с CountVectorizer, TfidfVectorizer, Kmeans, TSNE, NMF, TruncatedSVD, silhouette_score , MultinomialNB и LogisticRegression .
Очистка данных и исследовательский анализ данных (EDA)

- В наборе данных есть несколько НП, и я просто оставлю их.
- Столбец ReviewText будет моим основным столбцом для НЛП.
- Помимо столбца ReviewText, я создал еще один столбец под названием CombinedText, который объединяет столбцы Title и ReviewText вместе. Потому что я думаю, что могут быть некоторые скрытые данные, которые вы также можете получить из заголовка обзора.
- Наконец, я собираю очищенные данные для дальнейшего использования.
WordCloud
Следующее, что я делаю, это создаю WordCloud, чтобы видеть, какие слова люди говорят / используют чаще всего. Прежде чем я это сделаю, мне нужно:
- преобразовать мои тексты в нижний регистр
- удалите некоторые из менее полезных слов, которые могут присутствовать в обзорах, таких как платье, платья и т. д.
- Затем векторизуйте текстовые данные с помощью векторизатора Count и TF-IDF. Например:
count_vectorizer = CountVectorizer(ngram_range=(1, 2),
stop_words='english',
token_pattern="\\b[a-z][a-z]+\\b",
lowercase=True,
max_df = 0.6, max_features=4000)
tfidf_vectorizer = TfidfVectorizer(ngram_range=(1, 2),
stop_words='english',
token_pattern="\\b[a-z][a-z]+\\b",
lowercase=True,
max_df = 0.6, max_features=4000)
cv_data = count_vectorizer.fit_transform(df.ReviewTextLower)
tfidf_data = tfidf_vectorizer.fit_transform(df.ReviewTextLower)
код в основном говорит о векторизации текста в 1-граммовый и 2-граммовый (также пробовал с 3-граммовым), используя предварительно установленные английские стоп-слова из пакета, все и шаблон в нижнем регистре, игнорирует слова, которые имеют частоту выше 0,6 из документов, с максимум 4000 функций / размеров.
Затем я использую следующий код для создания WordCloud:
for_wordcloud = count_vectorizer.get_feature_names()
for_wordcloud = for_wordcloud
for_wordcloud_str = ' '.join(for_wordcloud)
wordcloud = WordCloud(width=800, height=400, background_color ='black',
min_font_size = 7).generate(for_wordcloud_str)
plt.figure(figsize=(20, 10), facecolor=None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad=0)
plt.show()

Тематическое моделирование
Есть еще один шаг, прежде чем я смогу провести тематическое моделирование, - это использовать LSA и NMF для уменьшения размера вводимых мной текстовых данных. Например:
# try using 10 dimensions n_comp = 10 lsa_tfidf = TruncatedSVD(n_components=n_comp) lsa_cv = TruncatedSVD(n_components=n_comp) nmf_tfidf = NMF(n_components=n_comp) nmf_cv = NMF(n_components=n_comp) lsa_tfidf_data = lsa_tfidf.fit_transform(tfidf_data) lsa_cv_data = lsa_cv.fit_transform(cv_data) nmf_tfidf_data = nmf_tfidf.fit_transform(tfidf_data) nmf_cv_data = nmf_cv.fit_transform(cv_data)
Затем мы можем провести моделирование темы, и ниже приведен пример вывода:

Вы можете создать разное количество тем, протестировав разное количество тем, чтобы найти лучшее количество, и посмотреть, имеют ли эти темы смысл для вас.
Кластеризация
Лучше стандартизировать ваши входные данные до среднего значения 0 и стандартного отклонения 1, прежде чем запускать алгоритмы кластеризации. Иными словами, поскольку все ваши функции могут быть не в одном масштабе, это может быть не то же самое, что увеличение на 1 единицу из функции a по сравнению с увеличением на 1 единицу из функции b.
# initialize standardscaler from sklearn.preprocessing import StandardScaler SS = StandardScaler() # transform my reducer data using standardscaler lsa_tfidf_data_sclaed = SS.fit_transform(lsa_tfidf_data) lsa_cv_data_sclaed = SS.fit_transform(lsa_cv_data) nmf_tfidf_data_scaled = SS.fit_transform(nmf_tfidf_data) nmf_cv_data_scaled = SS.fit_transform(nmf_cv_data)
Затем вы можете использовать алгоритм машинного обучения без учителя, чтобы создавать кластеры по разным темам или разным типам обзоров. В этом проекте я использовал KMeans, а также использовал оценки инерции и силуэта в качестве прокси, чтобы помочь мне определить, какое количество кластеров мне лучше всего использовать. Затем с помощью TSNE, чтобы визуализировать сгенерированные кластеры. Например:
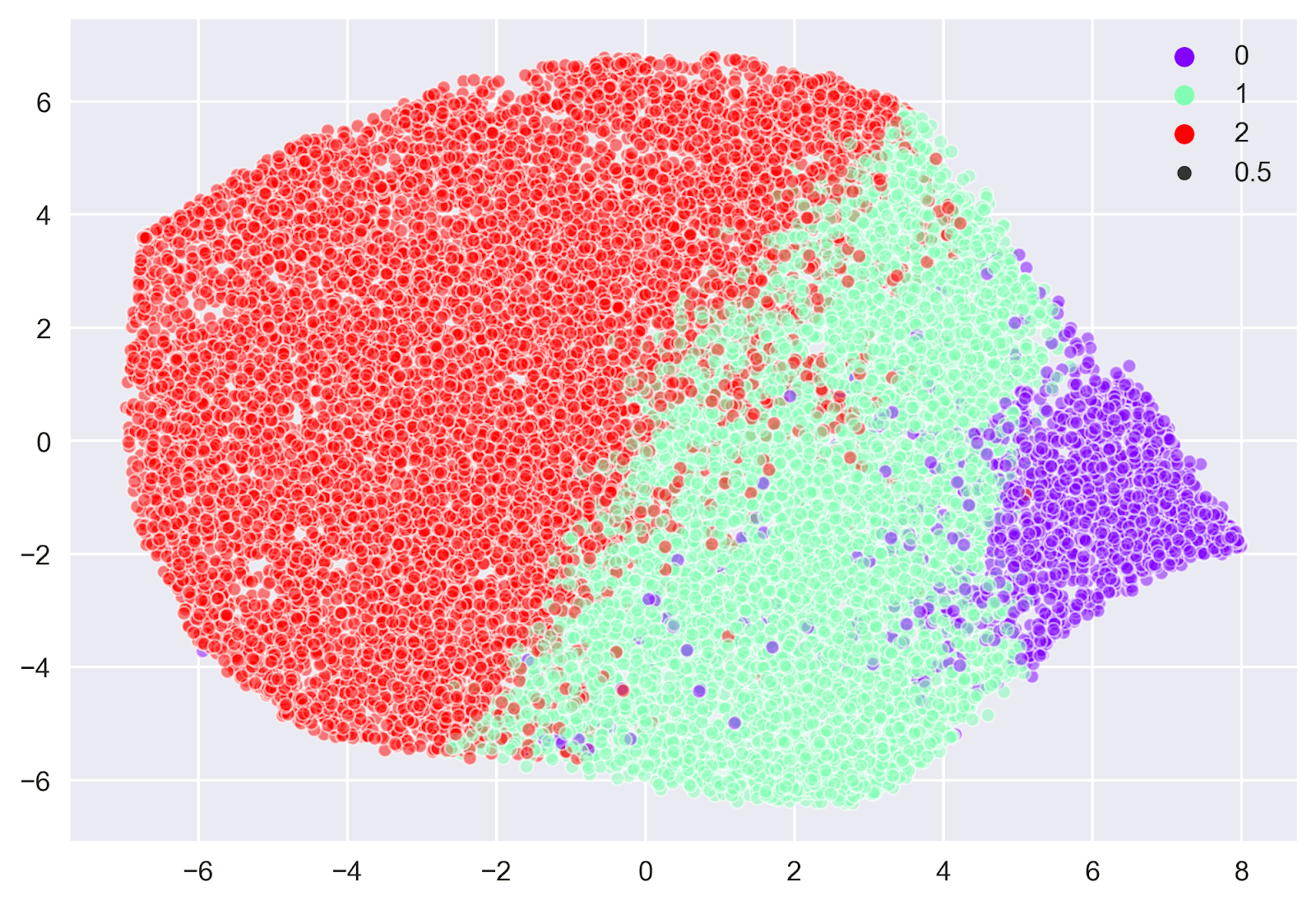


После того, как вы определили, сколько кластеров является лучшим, вы можете распечатать документы, которые находятся ближе всего к центроиду каждого кластера для экзаменов. Например:
indices_max = [index for index, value in enumerate(kmeans.labels_) if value==3]
for rev_index in indices_max[:5]:
print(rev_index, str(df.ReviewText[rev_index]))
print("\n")

Классификация
Еще одна вещь, которую мы можем попробовать отделить хорошие и плохие отзывы от анализа текстовых данных, - это выполнить задачу классификации.
В наших данных есть функция под названием Рейтинг, которая представляет собой рейтинг, который покупатель дает продукту, при этом 1 - наименее удовлетворен, а 5 - наиболее удовлетворен.
Мы можем установить столбец «Рейтинг» в качестве целевой переменной, а столбец «Спроектированный текст CombinedText» в качестве независимой переменной, чтобы посмотреть, сможем ли мы создать классификатор для автоматической классификации комментария.
Первое, что я сделал, - сгруппировал с 1 по 4 ранги вместе как плохой обзор (помечен как 1), а ранг 5 - это наш хороший обзор (помечен как 5). Эти два класса не являются полностью сбалансированными, но они находятся в приемлемом диапазоне. Я построил классификационные модели с наивными и логистическими классификаторами.


В качестве метрики, которую я использовал для оценки модели, я использовал оценку отзывчивость, потому что мне небезразличны случаи, когда я предсказывал, что обзор будет хорошим, но на самом деле это не так. Лучшая оценка отзыва, которую я получил, составляет 0,74 без особых усилий. Оценка могла бы быть лучше, если бы у модели было больше времени и исследований.

Извлеченный урок
- Обучение без учителя действительно сильно отличается от обучения с учителем по своей природе!
- Ожидается, что вы потратите много времени, пытаясь понять, как кластеризовать свои данные, кроме KMeans существует множество методов кластеризации.
- Занимаясь текстовой аналитикой или НЛП, вы можете ожидать, что потратите много времени на очистку текстовых данных для достижения наилучших результатов. Например, как решить, какие стоп-слова использовать в зависимости от контекста ваших данных и проблемы, которую вы хотите решить, как лемматизировать, как векторизовать, как уменьшить размерность и избежать проклятия размерности и т. Д.
В будущем
Если у меня будет возможность продлить проект, я хотел бы добавить следующее:
- Узнайте больше о различных типах алгоритмов кластеризации и методах НЛП.
- Добавьте новые стоп-слова.
- Создайте приложение-прототип Flask, чтобы создать автоматический процесс, чтобы рекомендовать (отделять) разные темы от комментариев пользователей.
Большое спасибо за чтение, и если вам интересно изучить мой код и ресурсы, которые я использовал, этот проект находится в моем репозитории на github.