Понимание алгоритма кластеризации пополам K-средних (визуальные эффекты и код)

Метод кластеризации пополам K-средних - это небольшая модификация обычного алгоритма K-средних, в котором вы фиксируете процедуру разделения данных на кластеры. Итак, аналогично K-средним, мы сначала инициализируем K центроидов (вы можете сделать это случайным образом или иметь некоторые предварительные). После чего применяем обычные K-средства с K = 2 (поэтому слово пополам). Мы продолжаем повторять этот шаг пополам, пока не будет достигнуто желаемое количество кластеров. После завершения первого деления пополам (когда у нас есть 2 кластера) можно подумать о нескольких стратегиях для выбора одного из кластеров и повторения всего процесса деления пополам и назначение внутри этого кластера - например: выбрать кластер с максимальной дисперсией или распределенный кластер, выбрать кластер с максимальным количеством точек данных и т. д.
Нет времени читать блог целиком? Затем посмотрите это короткое ‹60-секундное короткометражное видео на YouTube о том же -
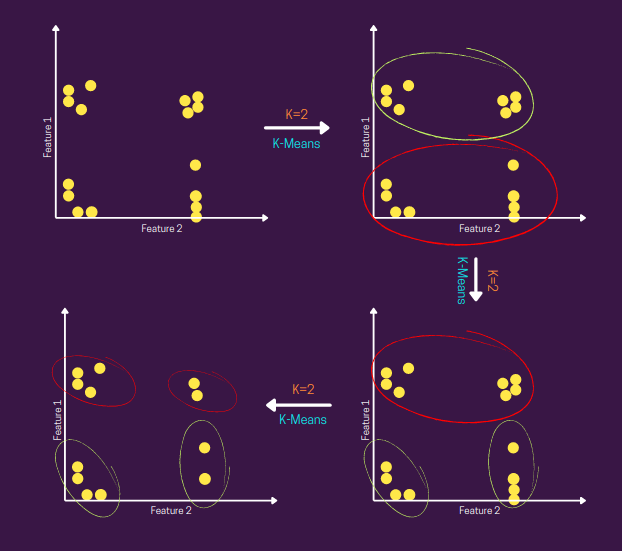
Вы можете визуализировать весь этот поток, как показано ниже -

Как вы можете видеть на рисунке выше, мы начинаем с предположения, что все данные находятся внутри одного кластера (1-й рис.), а после первого шага мы получаем 2 (деление пополам) кластеры, затем мы проверяем, достигнуто ли желаемое количество кластеров или нет. Если нет, мы выбираем один (красного цвета) из двух кластеров из предыдущего шага и снова применяем K-средства с K = 2, и мы повторяем «check »И« деление пополам ».
Как вы, возможно, уже догадались, это выглядит как смесь иерархической кластеризации и кластеризации K-средних. Потому что здесь вы строите дерево, которое представляет собой иерархическую структуру, в которой узел делится на два дочерних узла на основе стратегии K-средних и назначения.
Улучшение по сравнению с K-средними
В отличие от обычных K-средних, где мы вычисляем расстояние между каждой точкой данных и центроидом на каждом шаге до тех пор, пока не будут выполнены критерии сходимости, здесь вместо этого мы делаем это только один раз (первый шаг) и после то есть мы используем только точки данных в определенном кластере для расчета расстояния и дальнейшего разделения, что делает его более эффективным по сравнению с обычными K-средними. Он также может распознавать кластеры любой формы и размера, в отличие от K-среднего, который предполагает кластеры сферической формы. Я также нашел одну интересную исследовательскую статью, в которой сравнивается эффективность K-средних и пополам K-средних при анализе данных веб-журнала - Прочтите здесь.
Ограничения
Поскольку базовым методом кластеризации здесь по-прежнему является K-среднее, этот алгоритм также, вероятно, страдает ошибочной оценкой центра кластера в случае выбросов.
Совет. Метод кластеризации «Биссектриса K-Medoid» может помочь вам устранить указанное выше ограничение.
Код
Я буду использовать библиотеку Python Sklearn для реализации -
from sklearn.cluster import KMeans
import numpy as np
X = np.array([[1, 2], [2, 1], [1, 1.5], [1.5, 1],
[10, 2], [10, 4], [10, 0], [10, 1],
[1, 10], [2, 11], [1.5, 9], [1, 10.5],
[10.5, 9], [9, 9.5], [9.5, 9], [10, 10]])
K = 4
current_clusters = 1
while current_clusters != K:
kmeans = KMeans(n_clusters=2).fit(X)
current_clusters += 1
split += 1
cluster_centers = kmeans.cluster_centers_
sse = [0]*2
for point, label in zip(X, kmeans.labels_):
sse[label] += np.square(point-cluster_centers[label]).sum()
chosen_cluster = np.argmax(sse, axis=0)
chosen_cluster_data = X[kmeans.labels_ == chosen_cluster]
X = chosen_cluster_data
На рисунке ниже показано пошаговое руководство по приведенному выше примеру кода -
Короче говоря, при рассмотрении K-средних в качестве алгоритма выбора также неплохо попробовать пополам K-средних. По причинам, описанным выше, вполне возможно, что вы получите лучшие результаты с этим.
Надеюсь, вам понравилось читать этот блог. Спасибо за уделенное время!