
Графовые нейронные сети становятся все более популярными и широко используются в самых разных проектах.
В этой статье я помогу вам начать работу и понять, как работают графовые нейронные сети, а также попытаюсь ответить на вопрос «почему» на каждом этапе.
Наконец, мы также рассмотрим реализацию некоторых методов, о которых мы говорим в этой статье, в коде.
И не волнуйтесь — вам не нужно слишком много знать математику, чтобы понять эти концепции и научиться их применять.
Что такое график?
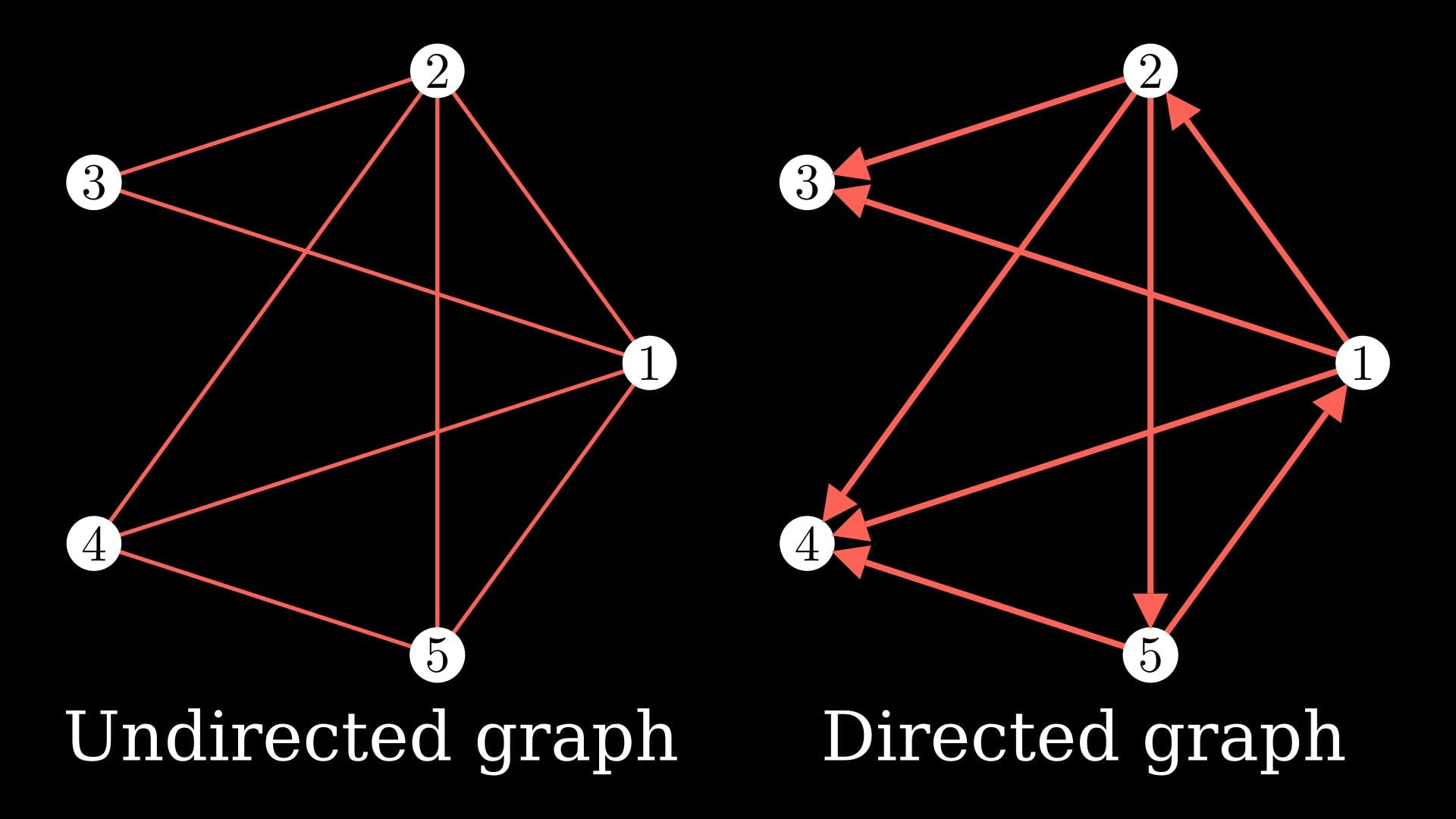
Проще говоря, граф — это набор узлов и ребер между узлами. На приведенной ниже диаграмме белые кружки представляют узлы, и они соединены ребрами, красными линиями.
Вы можете продолжить добавлять узлы и ребра к графу. Вы также можете добавить направления к ребрам, что сделает его ориентированным графом.
Что-то очень удобное — это матрица смежности, которая представляет собой способ выразить граф. Значения этой матрицы Aᵢⱼ определяются как:

Другой способ представить матрицу смежности - просто перевернуть направление, поэтому в том же уравнении \(A_{ij}\) будет равно 1, если вместо этого есть ребро \(i \rightarrow j\).
Более позднее представление на самом деле то, что я изучал в школе. Но часто в статьях по машинному обучению вы найдете первое используемое обозначение, поэтому в этой статье мы будем придерживаться первого представления.
Есть много интересных вещей, которые вы можете заметить из матрицы смежности. Во-первых, вы можете заметить, что если граф неориентированный, вы, по сути, получаете симметричную матрицу и более интересные свойства, особенно с собственными значениями этой матрицы.
Одна из таких интерпретаций, которая была бы полезна в контексте, заключается в том, что взятие степеней матрицы (Aⁿ)ᵢⱼ дает нам количество (направленных или ненаправленных) блужданий длины n между узлами i и j.
Зачем работать с данными в графиках?
Ну графы используются во всех видах общих сценариев, и у них есть много возможных применений.
Вероятно, наиболее распространенным применением графического представления данных является использование молекулярных графов для представления химических структур. Они помогли предсказать длины связей, заряды и новые молекулы.
С помощью молекулярных графиков вы можете использовать машинное обучение, чтобы предсказать, является ли молекула сильнодействующим лекарством.
Например, вы можете обучить графовую нейронную сеть предсказывать, будет ли молекула ингибировать определенные бактерии, и обучить ее различным соединениям, результаты для которых вам известны.
Затем вы можете применить свою модель к любой молекуле и в конечном итоге обнаружить, что молекула, которую раньше не замечали, на самом деле может работать как отличный антибиотик. Вот как Stokes et al. в своей статье (2020) предсказали появление нового антибиотика под названием галицин.
В другой интересной статье DeepMind (Прогнозирование ETA с помощью графовых нейронных сетей в Google Maps, 2021 г.) моделируются транспортные карты в виде графиков и запускается графовая нейронная сеть для повышения точности ETA до 50% в Google Maps.
В этой статье они разбивают маршруты путешествий на суперсегменты, которые моделируют часть маршрута. Это дало им структуру графа для работы, с которой они запускают графовую нейронную сеть.
Были и другие интересные работы, которые представляли естественные данные в виде графиков (социальные сети, электрические цепи, диаграммы Фейнмана и т. д.), в которых также были сделаны важные открытия.
А если подумать, то и стандартную нейронную сеть можно представить в виде графа 🤯.
Что мы можем сделать с графовыми нейронными сетями?
Давайте сначала начнем с того, что мы можем захотеть сделать с нашей графовой нейронной сетью, прежде чем понять, как мы это сделаем.
Один тип вывода, который мы могли бы захотеть от нашей графовой нейронной сети, — это весь уровень графа, чтобы иметь один выходной вектор. Вы можете связать этот тип выходных данных с предсказанием ETA или предсказанием энергии связи из молекулярной структуры из примеров, о которых мы говорили.
Другой тип вывода, который вам может понадобиться, — это прогнозы на уровне узла или ребра, и в итоге вы получите вектор для каждого узла или ребра. Вы можете связать это с примером, где вам нужно ранжировать каждый узел в предсказании или, возможно, предсказать валентный угол для всех связей с учетом молекулярной структуры.
Вас также может заинтересовать ответ на вопрос «Где разместить новое ребро или узел» или предсказать, где может появиться ребро или узел. Мы могли бы не только получить этот прогноз из графика, но и преобразовать некоторые другие данные в график.

Как вы могли догадаться, используя графовую нейронную сеть, мы сначала хотим сгенерировать выходной граф или латенты, на основе которых мы затем сможем работать над этим широким спектром стандартных задач.
Итак, что нам нужно сделать из скрытого графа (функции для каждого узла, представленного как \vector{hᵢ} для прогнозов на уровне графа, таковы:
- сначала придумайте способ агрегировать все векторы (например, просто суммировать) и
- затем создайте некоторую функцию, чтобы получить прогнозы:

А теперь довольно просто показать на высоком уровне, что нам нужно сделать из латентных, чтобы получить наши результаты.
Для выходных данных уровня узла мы бы просто передали один вектор узла в нашу функцию и получили прогнозы для этого узла:

Проблема с входами переменного размера
Теперь, когда мы знаем, что мы можем делать с графовыми нейронными сетями и почему вы можете захотеть представлять свои данные в графах, давайте посмотрим, как мы будем проводить обучение на данных графа.
Но во-первых, у нас есть проблема: графики — это, по сути, входные данные переменного размера. В стандартной нейронной сети, как показано на рисунке ниже, входной слой (показанный на рисунке как xᵢ) имеет фиксированное количество нейронов. В этой сети вы не можете внезапно применить сеть к входу переменного размера.

Но если вы помните, вы можете применять сверточные нейронные сети к входным данным переменного размера.
Давайте представим это на примере: у вас есть свертка с числом фильтров K = 5, пространственным экстентом F = 2, шагом S = 4 и без заполнения нулями P = 0. Вы можете передать (256 × 256 × 3) входных данных и получить (64 × 64 × 5) выходных данных (⌊(256–2+0)/(4)+1⌋, а также вы можете передать (96 × 96 × 6) входы и получить (24 × 24 × 5) выходы и т. д. — это практически не зависит от размера.
Это заставляет задуматься, можем ли мы черпать вдохновение из сверточных нейронных сетей.
Еще один действительно интересный способ решения проблемы переменных размеров входных данных, вдохновленный физикой, взят из статьи DeepMind Обучение моделировать сложную физику с помощью графовых сетей (2020).
Давайте начнем с некоторых частиц i, и каждая из этих частиц имеет определенное местоположение \vector{rᵢ} и некоторую скорость \vector{vᵢ}. Допустим, между этими частицами есть пружины, которые помогают нам понять любые взаимодействия.
Теперь эта система, конечно же, является графом: вы можете считать частицы узлами, а пружины — ребрами. Если теперь вспомнить простую школьную физику, сила = масса × ускорение — ну и как еще в этой системе можно обозначить суммарную силу, действующую на частицу? Это сумма сил, действующих на все соседние частицы.
Теперь вы можете написать (eᵢⱼ) представляет свойства края или пружины между i и j):

Я хотел бы обратить ваше внимание на то, что закон силы всегда один и тот же. Возможно, есть различия в свойствах пружины или лезвия, но вы все равно можете применить тот же закон. У вас может быть разное количество узлов и ребер, и вы все равно можете применить одно и то же уравнение движения.

Если вы присмотритесь, то интуиции, которые мы обсуждали, чтобы обойти проблему фиксированных входов, имеют аспект сходства с ними: в письменной форме довольно ясно, что второй подход учитывает соседние узлы и ребра и создает некоторую функцию (здесь сила ) из него. Я хотел указать, что принцип работы сверточных нейронных сетей не сильно отличается.
Как учиться на данных на графике
Теперь, когда мы обсудили, что может вдохновить нас на создание графовой нейронной сети, давайте теперь попробуем построить ее. Здесь мы увидим, как мы можем учиться на данных, находящихся на графике.
Мы начнем с обсуждения «Neural Message Passing», который аналогичен фильтрам в сверточной нейронной сети или силе, о которой мы говорили в предыдущем разделе.
Итак, допустим, у нас есть граф с 3 узлами (направленными или ненаправленными). Как вы могли догадаться, у нас есть соответствующее значение для каждого узла x₁, x₂ и x₃.
Как и в любой нейронной сети, наша цель — найти алгоритм для обновления этих значений узлов, аналогичный слою в графовой нейронной сети. И тогда вы, конечно, можете продолжать добавлять такие слои.
Итак, как вы делаете эти обновления? Одна из идей — использовать ребра в нашем графе. Для целей этой статьи предположим, что из трех узлов у нас есть ребро, указывающее от x₃ → x₁. Мы можем отправить сообщение по этому ребру, которое будет содержать значение, которое будет вычислено некоторой нейронной сетью.
Для этого случая мы можем записать это, как показано ниже (и мы также разберем, что это значит):

Мы будем использовать те же обозначения:
- m₃₁ — сообщение, переданное от узла 3 к узлу 1,
- \vector{h₃} - это значение узла 3,
- \vector{e₃₁} - значение ребра между узлом 3 и узлом 1, а
- fₑ представляет собой функцию «некоторой нейронной сети», которая зависит от всех этих значений, часто называемую функцией сообщения.
Допустим, у нас также есть ребро из x₂ → x₁. Мы можем применить то же выражение, которое мы создали выше, просто заменив номера узлов.
Если у вас больше узлов, вы захотите сделать это для каждого ребра, указывающего на узел 1. И самый простой способ собрать все это — просто суммировать их. Присмотритесь, и вы увидите, что это действительно похоже на интуицию от частиц, которую мы обсуждали ранее!
Теперь у вас есть совокупное значение сообщений, поступающих на узел 2, но вам все еще нужно обновить его веса. Поэтому мы будем использовать другую нейронную сеть, часто называемую сетью обновлений. Это зависит от двух вещей: вашего исходного значения узла 3, конечно, и совокупности сообщений, которые у нас были.
Просто сложив их вместе не только для узла 3 в нашем примере, но и для любого узла в любом графе, мы можем записать это как:

\vector{hᵢ’} — это наши значения узла обновления, а \vector{mᵢⱼ} — это сообщения, поступающие на узел i, которые мы вычислили ранее.
Затем вы примените эти же две нейронные сети fₑ и fᵥ для каждого из узлов, составляющих граф.
Здесь действительно важно отметить, что две нейронные сети, в которых мы должны обновлять значения наших узлов, работают с входными данными фиксированного размера, как стандартная нейронная сеть. Как правило, две нейронные сети, о которых мы говорили fₑ и fᵥ, представляют собой небольшие MLP.

Ранее мы говорили о различных видах выходных данных, которые нам интересны в получении от наших графовых нейронных сетей. Возможно, вы уже заметили, что при обучении нашей модели так, как мы говорили, мы сможем генерировать прогнозы на уровне узла: вектор для каждого узла.
Чтобы выполнить классификацию графа, мы хотим попытаться агрегировать все значения узлов, которые у нас есть после обучения нашей сети. Мы будем использовать слой считывания или пула (полностью понятно, откуда взялось это название).
Обычно мы можем создать функцию fᵣ в зависимости от набора значений узла. Но он также должен быть независимым от перестановок (не должен иметь значения при выборе маркировки узлов) и должен выглядеть примерно так:

Самый простой способ определить функцию считывания — суммировать значения всех узлов. Затем найти среднее, максимальное или минимальное значение или даже комбинацию этих или других инвариантных свойств перестановок, наиболее подходящих для данной ситуации. Ваш \(f_r\), как вы могли догадаться, тоже может быть нейронной сетью, которая часто используется на практике.
Идеи и интуиция, о которых мы только что говорили, создают нейронные сети передачи сообщений (MPNN), одну из самых мощных графовых нейронных сетей, впервые предложенную в Neural Message Passing for Quantum Chemistry (Gilmer et al. 2017).
Как изменить значения ребер
Теперь кажется, что мы действительно создали общую графовую нейронную сеть. Но вы можете видеть, что наша сеть сообщений требует \(e_{ij}\) свойства края — так же, как вы случайным образом инициализируете значения узлов при запуске.
Но в то время как значения узлов меняются на каждом шаге, значения ребер также инициализируются вами, но они не изменяются. Итак, нам нужно попытаться обобщить и это, расширить то, что мы только что видели.
Понимая, как работают обновления узлов, я думаю, вы можете очень легко применить что-то подобное и для функции обновления края.
U_{edge} — еще одна стандартная нейронная сеть:

Что-то, что вы также можете сделать с этой структурой, это то, что выходные данные U_{edge} уже являются свойствами уровня края — так почему бы просто не использовать их в качестве моего сообщения? Ну, вы могли бы сделать это, а также.
Обсуждение нейронной сети передачи сообщений
Нейронные сети передачи сообщений (MPNN) являются наиболее общими слоями графовой нейронной сети. Но это требует хранения и обработки пограничных сообщений, а также функций узла.
Это может стать немного проблематичным с точки зрения памяти и представления. Поэтому иногда они страдают от проблем с масштабируемостью и на практике применимы к графикам небольшого размера.
Как говорит Петар Величкович, «MPNN — это MLP домена графа». Мы рассмотрим некоторые расширения MPNN, а также способы реализации MPNN в коде.
Вы можете довольно легко применить именно то, о чем мы говорили, в PyTorch или TensorFlow — но попробуйте сделать это, и вы увидите, что это просто взрывает память.
Обычно то, что мы делаем со стандартными нейронными сетями, — это работа с пакетами данных. Таким образом, вы обычно передаете входной массив формы [размер пакета, количество входных нейронов] в нейронную сеть, чтобы она работала эффективно.
Теперь наше количество входных нейронов здесь не такое, как было указано ранее, и да, сверточные нейронные сети действительно имеют дело с изображениями произвольного размера. Но когда вы думаете о пакетах, вам нужно, чтобы все изображения были одинакового размера.
Есть несколько вещей, которые вы можете сделать:
- Работать с одним графом за раз (конечно, очень неэффективно)
- Вы также можете объединить свои графики в один большой график и не допускать передачи сообщений от одного из меньших графиков к другому меньшему графику. Это усложнило бы прогнозирование на уровне графика, и вам пришлось бы адаптировать функцию считывания.
- Вы также можете использовать рваные тензоры, которые представляют собой тензоры переменной длины: отличное руководство можно найти здесь.
- Снова вдохновитесь CNN: вы можете использовать отступы, чтобы в вашем пакете были, например, графики разных размеров. Итак, вы просто берете граф с 7 узлами и устанавливаете оставшиеся 3 узла равными 0. То же самое с графом с 8 узлами, устанавливаете оставшиеся 2 узла равными 0.
Другие популярные архитектуры GNN
В этом разделе я дам вам обзор некоторых других широко используемых слоев графовой нейронной сети.
Мы не будем рассматривать интуицию, лежащую в основе любого из этих слоев, и то, как каждая часть объединяется в функции обновления. Вместо этого я просто дам вам общий обзор этих методов. Вы, безусловно, могли бы прочитать оригинальные документы, чтобы лучше понять.
Граф сверточных сетей
Одной из самых популярных архитектур GNN является Graph Convolutional Networks (GCN) Kipf et al. который по существу является спектральным методом.
Спектральные методы работают с представлением графа в спектральной области. Спектральный здесь означает, что мы будем использовать собственные векторы Лапласа.
GCN основаны на вершине ChebNets, которые предполагают, что на представление признаков любого вектора должно влиять только его соседство k-hop. Мы будем вычислять нашу свертку, используя многочлены Чебышева.
В GCN это упрощается до \(K=1\). Мы начнем с определения матрицы степеней (построчное суммирование матрицы смежности):

Правило обновления сверточной сети графа после использования симметричной нормализации может быть записано, где H — матрица признаков, а W — матрица обучаемых весов:

Что касается узлов, вы можете записать это как где Nᵢ и Nⱼ — размеры окрестностей узлов:

Конечно, с GCN у вас больше нет граничных функций, и идея о том, что узел может отправлять значение по графу, которая была у нас с MPNN, обсуждалась ранее.
График сети внимания
Помните правило обновления узлов в GCN, которое мы только что видели? Термин Nᵢ и Nⱼ получен из матрицы степеней графа.
В Graph Attention Network (GAT) Величковича и др. Этот коэффициент αᵢⱼ вычисляется неявно. Таким образом, для конкретного ребра вы берете функции узла-отправителя, узла-получателя, а также функции ребра и пропускаете их через функцию внимания.

a может быть любым обучаемым, общим механизмом самоконтроля, таким как трансформаторы. Затем их можно нормализовать с помощью функции softmax по окрестностям:

Это составляет правило обновления GAT. Авторы предполагают, что это можно было бы значительно стабилизировать с помощью многоголового внимания к себе. Вот визуализация авторов статьи, показывающая шаг GAT.
Этот метод также очень масштабируем, поскольку он должен был вычислить скаляр для влияния от узла i к узлу j и записать вектор, как в MPNN. Но это, вероятно, не так широко, как MPNN.
Реализация кода для графовых нейронных сетей
С несколькими фреймворками, такими как PyTorch Geometric, TF-GNN, Spektral (на основе TensorFlow) и другими, реализовать графовые нейронные сети действительно довольно просто. Здесь мы увидим пару примеров, начиная с MPNN.
Вот как вы создаете нейронную сеть передачи сообщений, аналогичную той, что была описана в исходной статье «Передача нейронных сообщений для квантовой химии» с помощью PyTorch Geometric:
import torch.nn as nn
import torch.nn.functional as F
import torch_geometric.transforms as T
from torch_geometric.utils import normalized_cut
from torch_geometric.nn import NNConv, global_mean_pool, graclus, max_pool, max_pool_x
def normalized_cut_2d(edge_index, pos):
row, col = edge_index
edge_attr = torch.norm(pos[row] - pos[col], p=2, dim=1)
return normalized_cut(edge_index, edge_attr, num_nodes=pos.size(0))
class Net(nn.Module):
def __init__(self):
super().__init__()
nn1 = nn.Sequential(
nn.Linear(2, 25), nn.ReLU(), nn.Linear(25, d.num_features * 32)
)
self.conv1 = NNConv(d.num_features, 32, nn1, aggr="mean")
nn2 = nn.Sequential(nn.Linear(2, 25), nn.ReLU(), nn.Linear(25, 32 * 64))
self.conv2 = NNConv(32, 64, nn2, aggr="mean")
self.fc1 = torch.nn.Linear(64, 128)
self.fc2 = torch.nn.Linear(128, d.num_classes)
def forward(self, data):
data.x = F.elu(self.conv1(data.x, data.edge_index, data.edge_attr))
weight = normalized_cut_2d(data.edge_index, data.pos)
cluster = graclus(data.edge_index, weight, data.x.size(0))
data.edge_attr = None
data = max_pool(cluster, data, transform=transform)
data.x = F.elu(self.conv2(data.x, data.edge_index, data.edge_attr))
weight = normalized_cut_2d(data.edge_index, data.pos)
cluster = graclus(data.edge_index, weight, data.x.size(0))
x, batch = max_pool_x(cluster, data.x, data.batch)
x = global_mean_pool(x, batch)
x = F.elu(self.fc1(x))
x = F.dropout(x, training=self.training)
return F.log_softmax(self.fc2(x), dim=1)
Вы можете найти полный Colab Notebook, демонстрирующий реализацию здесь, и он действительно довольно тяжелый. Это также довольно просто реализовать в TensorFlow, и вы можете найти полное руководство Примеры Keras здесь.
Реализация GCN также довольно проста с PyTorch Geometric. Вы также можете легко реализовать это с помощью TensorFlow, и вы можете найти полный блокнот Colab здесь.
class Net(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = GCNConv(dataset.num_features, 16, cached=True,
normalize=not args.use_gdc)
self.conv2 = GCNConv(16, dataset.num_classes, cached=True,
normalize=not args.use_gdc)
def forward(self):
x, edge_index, edge_weight = data.x, data.edge_index, data.edge_attr
x = F.relu(self.conv1(x, edge_index, edge_weight))
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index, edge_weight)
return F.log_softmax(x, dim=1)
А теперь давайте попробуем реализовать GAT. Полный блокнот Colab вы можете найти здесь.
class Net(torch.nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv1 = GATConv(in_channels, 8, heads=8, dropout=0.6)
# On the Pubmed dataset, use heads=8 in conv2.
self.conv2 = GATConv(8 * 8, out_channels, heads=1, concat=False,
dropout=0.6)
def forward(self, x, edge_index):
x = F.dropout(x, p=0.6, training=self.training)
x = F.elu(self.conv1(x, edge_index))
x = F.dropout(x, p=0.6, training=self.training)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=-1)
Заключение
Спасибо, что были со мной до конца. Я надеюсь, что вы усвоили кое-что о графовых нейронных сетях и вам понравилось читать, как эти интуитивные представления для графовых нейронных сетей формируются в первую очередь.
Если вы узнали что-то новое или вам понравилось читать эту статью, поделитесь ею, чтобы другие могли ее увидеть. А пока, увидимся в следующем посте!
Наконец, для мотивированного читателя, среди прочего, я также рекомендую вам прочитать оригинальную статью Модель графовой нейронной сети, в которой впервые была предложена GNN, поскольку она действительно интересна. Архив статьи в открытом доступе находится здесь. Эта статья также черпает вдохновение из Теоретических основ графовых нейронных сетей и CS224W, которые я предлагаю вам проверить.
Вы также можете найти меня в Твиттере @rishit_dagli, где я пишу о машинном обучении и немного об Android.
Первоначально опубликовано на https://www.freecodecamp.org 1 февраля 2022 г.