Линейная регрессия — это статистический метод, который уже много лет используется в прогностическом моделировании. Это простой, но мощный метод, который позволяет нам прогнозировать переменную количественного отклика на основе одной или нескольких переменных-предикторов.
В этом сообщении блога мы обсудим, что такое линейная регрессия, как она работает и как ее можно использовать в прогнозном моделировании.
Что такое линейная регрессия
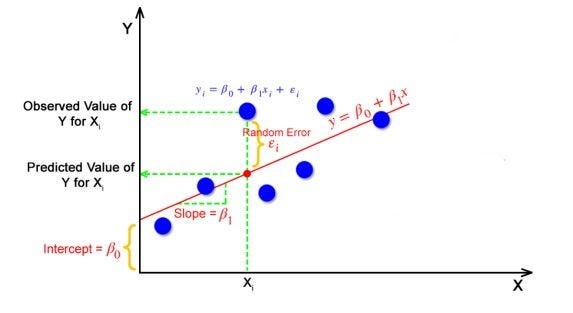
Линейная регрессия — это статистический метод, используемый для моделирования связи между зависимой переменной (Y) и одной или несколькими независимыми переменными (X). Цель линейной регрессии — найти наиболее подходящую линию данных, которая минимизирует сумму квадратов остатков (разница между прогнозируемыми и фактическими значениями).
Уравнение для простой модели линейной регрессии:
Y = β0 + β1X + ε
Где Y — зависимая переменная, X — независимая переменная, β0 — точка пересечения, β1 — наклон, а ε — ошибка. Термин ошибки представляет собой изменчивость Y, которую нельзя объяснить предикторной переменной X.
Типы линейной регрессии
Существует два основных типа линейной регрессии:
- Простая линейная регрессия
- Множественная линейная регрессия.
Простая линейная регрессия включает только одну независимую переменную и одну зависимую переменную. Уравнение для простой модели линейной регрессии:
Y = β0 + β1x + ε
где Y — зависимая переменная, x — независимая переменная, β — наклон линии регрессии, а β0 — точка пересечения.
Множественная линейная регрессия включает две или более независимых переменных и одну зависимую переменную. Уравнение для модели множественной линейной регрессии:
Y = β0 + β1X + β2X2 + …+ βnXn
где y — зависимая переменная, X1, X2, …, Xn — независимые переменные, а β0, β1, β2…βn — коэффициенты регрессии.
Как работает линейная регрессия?
Линейная регрессия работает, находя наиболее подходящую линию по данным, которая минимизирует сумму квадратов остатков. Эта линия называется линией регрессии и определяется уравнением:
Ŷ = β0 + β1X
Где Ŷ — прогнозируемое значение Y на основе значения X, β0 — точка пересечения, а β1 — наклон.
Чтобы найти наиболее подходящую линию, мы используем метод, называемый регрессией наименьших квадратов. Этот метод включает в себя нахождение значений β0 и β1, минимизирующих сумму квадратов невязок. Квадраты остатков — это разница между прогнозируемым значением и фактическим значением, возведенная в квадрат.
Как только мы нашли значения β0 и β1, которые минимизируют сумму квадратов остатков, мы можем использовать линию регрессии для прогнозирования новых данных.
Цель линейной регрессии состоит в том, чтобы найти значения m и b, которые минимизируют разницу между предсказанными значениями y и фактическими значениями Y. Это делается путем минимизации суммы квадратов разностей между предсказанными значениями y и фактические значения Y, известные как остаточная сумма квадратов (RSS).
Как можно использовать линейную регрессию в прогнозном моделировании
Линейную регрессию можно использовать во многих различных приложениях прогнозного моделирования. Например, его можно использовать для прогнозирования цены дома на основе его размера и местоположения, для прогнозирования продаж продукта на основе его цены и рекламного бюджета или для прогнозирования количества часов солнечного света на основе времени год и место.
Линейную регрессию также можно использовать в более сложных приложениях прогнозного моделирования. Например, его можно использовать в качестве строительного блока для более продвинутых алгоритмов машинного обучения, таких как нейронные сети или деревья решений.
Оценка производительности линейной регрессии с использованием MSE и RMSE
После построения модели линейной регрессии важно оценить ее производительность. Наиболее часто используемые показатели для оценки производительности моделей линейной регрессии — это среднеквадратическая ошибка (MSE) и среднеквадратическая ошибка (RMSE).
MSE рассчитывается путем получения среднего значения квадратов разностей между предсказанными значениями y и фактическими значениями y:
MSE = (1/n) * Σ(yi — ŷi)²
где n — количество наблюдений, yi — фактическое значение зависимой переменной, а ŷi — прогнозируемое значение зависимой переменной.
RMSE — это просто квадратный корень из MSE:
RMSE = sqrt(MSE)
MSE и RMSE обеспечивают меру того, насколько хорошо модель способна предсказывать зависимую переменную. Более низкая MSE или RMSE указывает на более подходящую модель. Эти показатели можно использовать для сравнения производительности различных моделей линейной регрессии и выбора лучшей модели для данного приложения.
Функция стоимости для линейной регрессии
Функция стоимости является мерой того, насколько хорошо модель линейной регрессии соответствует обучающим данным. Цель линейной регрессии — минимизировать функцию стоимости, чтобы прогнозируемые значения зависимой переменной были как можно ближе к фактическим значениям.
Наиболее часто используемой функцией стоимости для линейной регрессии является среднеквадратическая ошибка (MSE). MSE измеряет среднеквадратичную разницу между прогнозируемыми значениями зависимой переменной и фактическими значениями. Уравнение для MSE:
MSE = (1/n) * Σ(yi — ŷi)²
где n — количество наблюдений, yi — фактическое значение зависимой переменной, а ŷi — прогнозируемое значение зависимой переменной.
Функция стоимости является ключевым компонентом алгоритма градиентного спуска. Алгоритм градиентного спуска итеративно обновляет параметры модели, чтобы минимизировать функцию стоимости. Алгоритм работает, вычисляя градиент функции стоимости по отношению к каждому параметру и обновляя параметры в направлении отрицательного градиента. Путем многократного обновления параметров алгоритм постепенно сходится к оптимальным значениям, минимизирующим функцию стоимости.
Таким образом, функция стоимости является мерой того, насколько хорошо модель линейной регрессии соответствует обучающим данным, а цель алгоритма градиентного спуска состоит в том, чтобы минимизировать функцию стоимости путем итеративного обновления параметров модели.
Оптимизация линейной регрессии с градиентным спуском
Градиентный спуск — это один из алгоритмов оптимизации, который оптимизирует функцию стоимости (целевую функцию) для достижения оптимального минимального решения. Чтобы найти оптимальное решение, нам нужно уменьшить функцию стоимости (MSE) для всех точек данных. Это делается путем итеративного обновления значений B0 и B1, пока мы не получим оптимальное решение.
Модель регрессии оптимизирует алгоритм градиентного спуска для обновления коэффициентов линии за счет уменьшения функции стоимости путем случайного выбора значений коэффициентов, а затем итеративного обновления значений для достижения функции минимальной стоимости.

Функция стоимости для линейной регрессии обычно определяется как среднеквадратическая ошибка (MSE):
J(θ) = (1/2m) * Σ(hθ(xi) — yi)²
где J(θ) — функция стоимости, m — количество обучающих примеров, hθ(xi) — прогнозируемое значение линейной регрессии.
Предположения линейной регрессии
Линейная регрессия — это статистический метод, используемый для моделирования связи между зависимой переменной и одной или несколькими независимыми переменными. Однако есть несколько предположений, которые должны выполняться, чтобы линейная регрессия была действительным и надежным методом прогнозирования значений зависимой переменной. Ниже приведены общие предположения линейной регрессии:
- Линейность: взаимосвязь между зависимой переменной и независимыми переменными должна быть линейной. Это означает, что изменение зависимой переменной должно быть пропорционально изменению независимой переменной (переменных).

- Независимость. Наблюдения должны быть независимыми друг от друга. Другими словами, значение одного наблюдения не должно зависеть от значения другого наблюдения.

- Гомоскедастичность: дисперсия зависимой переменной должна быть постоянной на всех уровнях независимых переменных.

- Нормальность: остатки должны быть нормально распределены. Нормальность означает, что распределение остатков должно быть симметричным и колоколообразным.

- Отсутствие мультиколлинеарности. Если вы используете несколько независимых переменных, они не должны сильно коррелировать друг с другом. Мультиколлинеарность может затруднить определение влияния каждой независимой переменной на зависимую переменную.

- Нет влиятельных выбросов: выбросы могут существенно повлиять на линию регрессии и результаты анализа. Вы можете определить выбросы, создав диаграмму рассеяния данных и найдя точки данных, которые находятся далеко от других точек.

Эти допущения линейной регрессии важны для обеспечения того, чтобы модель была валидной и надежной для прогнозирования. Нарушение этих допущений может привести к предвзятым и неверным результатам. Поэтому важно тщательно изучить данные и проверить эти предположения, прежде чем применять линейную регрессию.
Заключение
Линейная регрессия — это мощный инструмент прогнозного моделирования, который позволяет нам моделировать взаимосвязь между зависимой переменной и одной или несколькими независимыми переменными. Найдя наиболее подходящую линию данных, мы можем делать прогнозы относительно новых данных на основе значений переменных-предикторов. Линейная регрессия — это простой, но мощный метод, который уже много лет используется в самых разных приложениях.