LLM были популярны с тех пор, как ChatGPT был выпущен для широкой публики. Хотя большинство людей, занимающихся прикладным ИИ, знают, как использовать API, возможно, им не хватает математического понимания того, «почему» это работает. Вот всесторонняя деконструкция LLM в целом и Transformers в частности с математической точки зрения.
ПРИМЕЧАНИЕ. Этот блог длиннее обычного и служит универсальным источником информации о том, как и почему работают LLM. Вы можете легко пропустить разделы, в которых вы уже хорошо разбираетесь. Вы можете пропустить математические уравнения и при этом многое понять.
Вы можете скачать PDF, если хотите, отсюда. Ссылка на PDF

На самом высоком уровне доминирующие модели нейронной трансдукции, такие как GPT-4 и Google Bard, в основном основаны на архитектуре кодер-декодер с использованием Transformer и Attention. Понимание внутренней работы и математики, лежащих в основе Transformers, имеет основополагающее значение, если вам нужно понять LLM.
В архитектуре Transformer кодировщик берет последовательность представлений токенов (x1, …, xn) и преобразует ее в соответствующую последовательность непрерывных представлений (z1, …, zn), называемую вектором контекста. Затем декодер берет вектор контекста и генерирует ряд выходных токенов (y1, …, ym). Входная последовательность N и выходная последовательность M не обязательно должны быть одинаковой длины.
Прелесть в том, что эти последовательности токенов могут быть какими угодно. Например, они могут быть:
- Слова, образующие предложения
- Музыкальные мотивы, образующие мелодию
- Мотивы/аллели из геномов
- Пиксели изображения
- Временные ряды с фондового рынка
- Химические структуры медицины
- Фонемы или звуки речи в разговорной речи
- Точки данных в таблице
- Жесты или мозговые волны для управления интерфейсами.
- Товары в корзине или история покупок
- Шаги в рецепте или процедуре
- Полипептидные биологические последовательности для образования белка
Как единый архитектурный паттерн, такой как Transformer и Attention, может ассимилировать, понять и закодировать контекст, значение, сущность и дискурс последовательности токенов? Почему это работает?
Что это за Колдовство?
Начнем с того, что Transformer следует многоуровневым, самостоятельным и точечным, полностью связанным слоям как для кодировщика, так и для декодера.
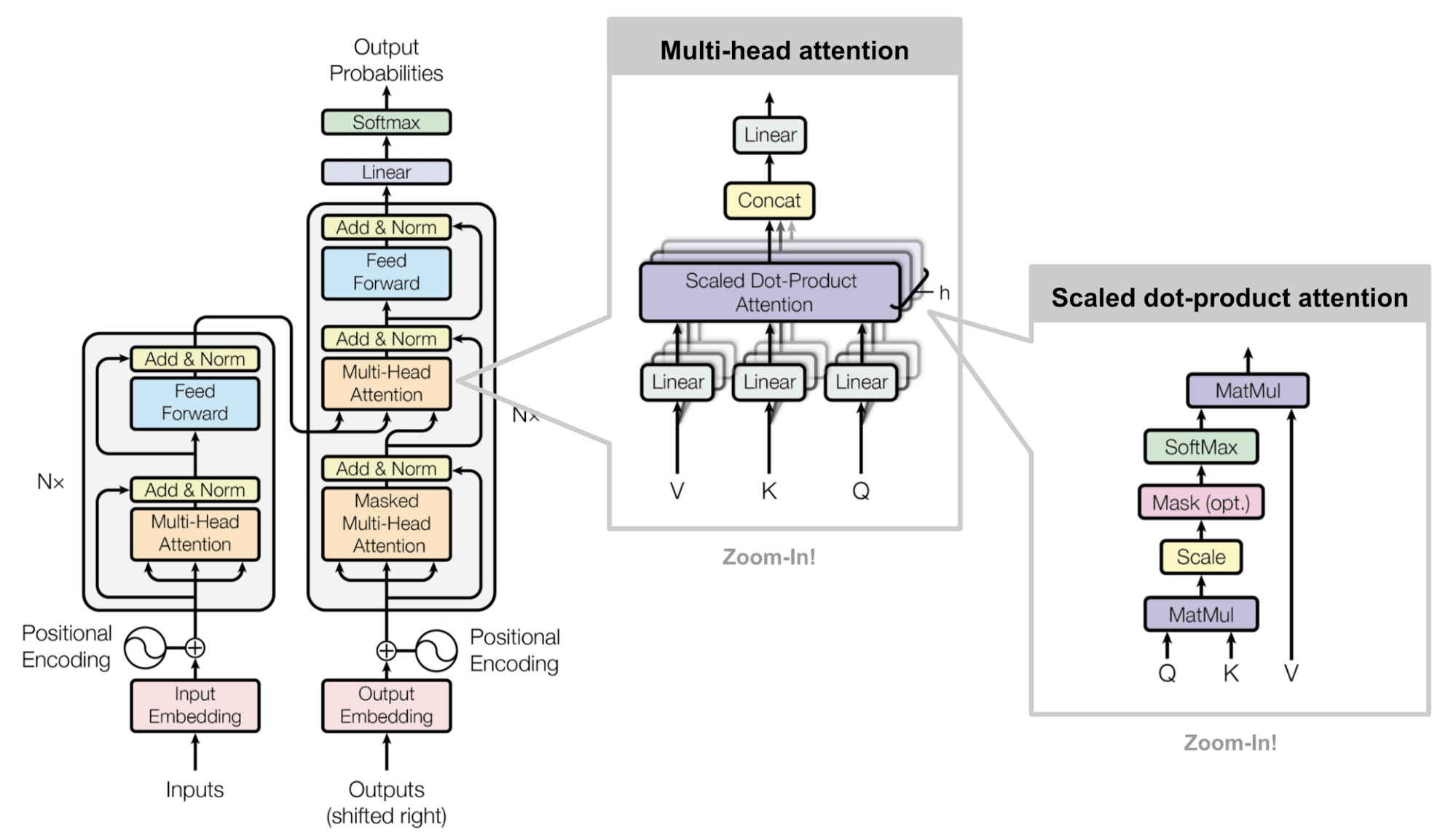
Я не собираюсь освещать то, что уже объяснено в Vaswani et al. газета под названием Внимание — это все, что вам нужно. Вы можете узнать это, прочитав статью непосредственно. Вместо этого я буду дразнить самые важные вопросы и путаницу в понятиях и математике. Я должен вести этот блог, потому что после общения со многими людьми, работающими в области прикладного ИИ, я понял, что они все еще в замешательстве или нуждаются в разъяснении того, как и почему все работает.
Рецепт внимания
Трансформеры используют внимание, чтобы узнать контекст, значение и сущность каждого слова, предложения и абзаца. О Внимании я писал здесь «Что за шумиха вокруг Внимания в Генеративном ИИ?»
Внимание работает путем вычисления набора весов, которые показывают относительную важность различных элементов для предсказания каждого элемента. Таким образом, модель может выборочно сосредоточиться на частях последовательности, которые наиболее важны для прогнозирования. Это особенно полезно в задачах, где между различными частями последовательности существуют долгосрочные зависимости.
Давайте воспользуемся этим рисунком в качестве ориентира, который поможет нам понять пошаговый процесс, необходимый для достижения внимания.

Хлебные крошки, которые мы пройдем, чтобы понять, как работают LLM, следующие:
Токенизация › Внедрение ввода › Постальное кодирование › Q, K, V › Оценка внимания › Многоголовое внимание › (Декодер) Маскированное внимание › (Декодер) Импорт K, V.
Шаг 1 — Токенизация
Давайте немного разберем внутреннюю работу. Внимание непосредственно не работает со словами. Вместо этого он работает с вложениями слов.
INSIGHT for LLM (Или зачем мне это знать): существует 171 146 оксфордских словарей и миллионы технических слов в английском языке. Вместо того, чтобы пытаться использовать большой корпус слов, вы можете сжать их в фиксированный набор токенизации, который может представлять все слова и их расширения с использованием схемы токенизации.
Вложения могут исходить из схемы токенизации, которая особенно полезна для имеющейся последовательности (язык против пикселей против гена). Разговорные языки могут быть подвергнуты следующим схемам токенизации.
- Токенизация пробелов: этот простой метод разбивает текст на основе символов пробелов (пробелов, табуляции и новой строки). Это быстро, но может не подходить для языков без четких границ слов или при работе с пунктуацией.
- Токенизация на основе правил: этот метод использует правила и регулярные выражения для конкретного языка для разделения текста на токены. Общие токенизаторы на основе правил включают токенизатор Penn Treebank для английского языка и токенизатор Moses для нескольких языков. Токенизаторы на основе правил могут работать с пунктуацией и сокращениями, но могут иметь проблемы со словами, не входящими в словарь, сленгом или языковыми вариациями.
- Статистическая маркировка. Статистические лексемы изучают границы лексем на основе частоты последовательностей символов в большом текстовом корпусе. Они могут адаптироваться к языковым вариациям и в некоторой степени обрабатывать слова, не входящие в словарь. Примеры методов статистической токенизации включают SentencePiece и алгоритм Витерби.
- Токенизация подслов: токенизаторы подслов разбивают текст на более мелкие единицы, такие как подслова или символы, что позволяет модели обрабатывать слова, не входящие в словарь, и лучше обобщать. Общие методы токенизации подслов включают кодирование пар байтов (BPE), WordPiece и языковую модель Unigram.
- Морфологическая лексема: этот метод разбивает текст на морфемы, которые являются наименьшими значимыми единицами в языке. Морфологическая токенизация может быть особенно полезна для языков со сложной морфологией, таких как турецкий или финский. Такие инструменты, как Stanford Morphological Analyzer или алгоритм Morfessor, можно использовать для морфологической токенизации.
Токенизация BPE: наиболее полезной является токенизация BPE, которая называется кодированием байтовых пар. Byte Pair Encoding (BPE) — это алгоритм сжатия данных, адаптированный для использования в обработке естественного языка в качестве метода токенизации подслов. В контексте языковых моделей целевой словарь на основе BPE относится к словарю, построенному с использованием алгоритма BPE для представления текста со словарем фиксированного размера, состоящим из единиц подслов.
BPE работает путем итеративного слияния наиболее часто встречающихся пар символов или единиц подслов в обучающих данных. Делая это, BPE изучает набор единиц подслов, которые можно использовать для представления любого текста в обучающих данных. Это позволяет модели обрабатывать редкие или отсутствующие слова, разбивая их на более мелкие подслова, присутствующие в словаре BPE.
Целевой словарь на основе BPE может состоять из отдельных символов, общих единиц подслов (например, «ing», «pre», «ation») и целых слов, которые часто встречаются в обучающих данных. Этот тип словарного запаса помогает языковым моделям лучше обобщать, поскольку он уменьшает проблему разреженности данных и позволяет модели обрабатывать широкий спектр языковых вариантов.
Например, OpenAI GPT-3 использует целевой словарь на основе BPE с 50 257 токенами, что позволяет ему обрабатывать широкий спектр текстовых входов и генерировать значимые выходные данные в различных доменах.
Вот несколько примеров, иллюстрирующих, как работает токенизация BPE: Давайте рассмотрим следующее предложение: «ChatGPT — это языковая модель ИИ, разработанная OpenAI».
- Потенциальной токенизацией этого предложения на основе BPE может быть: [«Чат», «G», «PT», «есть», «an», «AI», «язык», «модель», «разработано», by», «Открыть», «AI», «.»]
- Обратите внимание, как слово «ChatGPT» разбито на три подслова: «Chat», «G» и «PT».
- Теперь давайте рассмотрим предложение с редким или выходящим из словаря словом: «Квокка — маленький сумчатый абориген Западной Австралии».
- Потенциальная токенизация этого предложения на основе BPE может быть следующей: [«The», «qu», «ok», «ka», «is», «a», «small», «mars», «up», « ial», «родной», «до», «западный», «Австралия», «.»]
- В данном случае редкое слово «квокка» было разложено на подсловные единицы «цю», «ок» и «ка».
Повторное создание выходных данных. Чтобы воссоздать выходную последовательность из токенов BPE (Byte Pair Encoding), необходимо отменить процесс токенизации, который использовался для кодирования исходной последовательности.
Вот шаги для воссоздания выходной последовательности из токенов BPE:
- Создайте словарь, который сопоставляет каждый токен BPE с соответствующей парой байтов.
- Переберите токены BPE в выходной последовательности.
- Для каждого токена BPE найдите соответствующую пару байтов в словаре и замените токен BPE этой парой байтов.
- Объедините полученные пары байтов, чтобы сформировать выходную последовательность.
Шаг 2 — Входные вложения
Внедрение входных данных — это метод, используемый в обработке естественного языка (NLP) и других областях для преобразования дискретных токенов в непрерывные векторные представления, которые могут легче обрабатывать модели машинного обучения. Основная идея встраивания входных данных состоит в том, чтобы сопоставить каждый токен во входной последовательности с многомерным вектором в непрерывном пространстве встраивания.
ПОНИМАНИЕ: кодирование токенов в многомерное векторное пространство делает две волшебные вещи для LLM.
- Во-первых, он предоставляет адрес фиксированного размера в многомерном векторном пространстве, которое может быть вектором с плавающей запятой размером 512.
- Во-вторых, слова, которые встречаются вместе, а также ближе к семантическому значению, будут группироваться вместе в многомерном векторном пространстве, где расстояние между словами меньше. Таким образом, векторы FP двух похожих слов также будут ближе.
Второй момент очень важен для понимания того, как токены получают «числовое» значение и как это числовое значение имеет связанное с ним семантическое значение (они не случайны). Поэтому, когда вы вычисляете оценку на основе этих значений, вы пытаетесь манипулировать многомерным векторным пространством, контекстуально перемещаясь по нему на основе последовательности слов.
Механизм внимания использует эти числовые значения, чтобы понять контекстуальные отношения слов в последовательности.
Эти модели называются распределительными семантическими моделями или сокращенно DSM. Распределительные семантические модели — это класс моделей, которые представляют значение слов на основе свойств распределения их контекстов в большом корпусе текста. Вот несколько примеров семантических моделей распределения:
- Word2Vec: Word2Vec — это модель на основе нейронной сети, которая изучает плотные, непрерывные векторные представления (встраивания) слов на основе шаблонов их совместного появления. Вложения Word2Vec широко используются в анализе тональности и машинном переводе.
- GloVe: GloVe (глобальные векторы) — это модель на основе подсчета, которая изучает векторные представления слов на основе статистики совпадения слов. Было показано, что встраивание GloVe обеспечивает эффективную классификацию текста и распознавание именованных объектов.
- FastText: FastText — это модель на основе нейронной сети, которая расширяет Word2Vec, представляя слова в виде наборов символьных n-грамм в дополнение к их встраиваниям в полные слова. Это позволяет FastText собирать информацию о единицах подслов, такую как префиксы и суффиксы, которые могут быть полезны для обработки слов вне словаря и морфологически богатых языков.
- Скрытый семантический анализ (LSA): LSA — это модель на основе подсчета, которая использует SVD и изучает низкоразмерные векторные представления слов на основе шаблонов совместного появления слов. LSA — это линейная модель, означающая, что она предполагает, что значение слова является линейной комбинацией значений его контекстных слов. LSA используется для поиска информации.
- Гиперпространственный аналог языка (HAL): HAL — это DSM, использующий SVD и используемый для лексической замены и устранения неоднозначности словесного смысла.
Тип встраивания ввода, используемый после BPE, зависит от конкретной задачи и требований модели. Однако, как правило, Transformers используют фиксированные вложения, такие как Word2Vec. Word2Vec поставляется в двух вариантах. Пропустить грамм и непрерывный набор слов (CBoW).
Skip-gram обычно считается лучшим, чем CBOW, для обучения встраиванию слов при работе с большими объемами текстовых данных или когда целевые слова редки, потому что он может обрабатывать больше шума в данных и может фиксировать более тонкие отношения между словами.
Skip Gram. Модель skip-gram предполагает, что слово может использоваться для создания окружающих его слов в текстовой последовательности. Возьмем в качестве примера текстовую последовательность «проблемы», «превращение», «в», «банковское дело», «кризисы», «как». Давайте выберем «в» в качестве центрального слова и установим размер окна контекста равным 2.

Учитывая центральное слово «в», модель скип-граммы рассматривает условную вероятность генерации контекстных слов, которые находятся не более чем в 2 словах от центрального слова. Это может быть выражено математически как:
P(′проблемы′,′обращение′,′банковское дело′,′кризисы′ ∣ ′в′)
В предположении, что слова контекста генерируются независимо при заданном центральном слове (т. е. условная независимость), приведенная выше условная вероятность может быть переписана как:
P(′проблемы′∣′в′) × P(′превращение ′∣′в′) × P(′банковское дело′∣′в′) × …
Таким образом, условная вероятность генерации любого слова контекста при заданном центральном слове может быть смоделирована операцией softmax над векторными скалярными произведениями.

где набор словарных индексов V = {0,1,…,|V|−1}. Рассмотрим текстовую последовательность длины T, где слово на временном шаге t обозначается как w(t). Предполагая, что слова контекста генерируются независимо для любого центрального слова, функция правдоподобия модели пропусков грамм для размера окна контекста m представляет собой вероятность создания всех слов контекста для любого центрального слова, что может быть выражено математически как:

где j — индекс слова контекста относительно центрального слова, а вероятность P(w(t+j) | w(t)) определяется функция софтмакс:

Здесь v_{w(t+j)} и u_{w(t)} являются векторами вложения для контекстного слова w(t+j) и центрального слова w(t) соответственно. Сумма в знаменателе берется по всем словам словаря, обозначенного набором индексов V.
Шаг 3 — Позиционное кодирование
Нелинейные RNN, где последовательность токенов подается в модель один за другим, модели генеративного ИИ на основе Transformer НЕ обрабатывают последовательность токенов в том порядке, в котором они отправляются. Вместо этого преобразователи обрабатывают токены параллельно. Так как токены обрабатываются параллельно, в архитектуре требуется индикатор порядка токенов. Или, другими словами, архитектура модели требует умного способа узнать «положение» токена относительно всех других токенов. Здесь в игру вступает Позиционное кодирование. (Обратите внимание, что рекуррентные или сверточные модели в этом не нуждаются.)
В Трансформерах используются различные типы схем позиционного встраивания, некоторые из которых:
- Изученные позиционные вложения: в этой схеме модель изучает отдельное вложение для каждой позиции во входной последовательности. Эти вложения изучаются вместе с другими параметрами модели во время обучения.
- Фиксированные позиционные вложения: в этой схеме позиционные вложения фиксированы и не меняются во время обучения. Вложения могут быть предварительно вычислены на основе некоторой функции положения, такой как функции синуса и косинуса.
- Гибридные позиционные вложения: в этой схеме используется комбинация изученных и фиксированных позиционных вложений. Например, модель может использовать фиксированные вложения для позиций до определенного порога и изученные вложения для позиций за пределами этого порога.
- Относительные позиционные вложения: в этой схеме позиционные вложения фиксируют относительные положения токенов во входной последовательности. Это позволяет модели обобщать более длинные последовательности, чем те, которые видны во время обучения.
- Сверточные позиционные вложения: в этой схеме сверточные нейронные сети используются для вычисления позиционных вложений. Сверточные слои позволяют модели фиксировать локальные зависимости между соседними токенами, в то время как позиционные вложения собирают информацию о глобальном положении.
Васвани и др. paper говорит о позиционном кодировании, которое представляет собой вектор, который добавляется к каждому входному вложению (после шага 2). Эти векторы следуют определенному шаблону, который изучает модель, что помогает ей определять положение каждого слова или расстояние между разными словами в последовательности.
Традиционное кодирование основано на синусоидальных функциях различных частот и фаз, которые представляют относительные положения маркеров во входной последовательности.

Вот визуализация положения токена в его измерении внедрения с использованием традиционного позиционного кодирования.

Математически позиционные вложения могут быть представлены в виде матрицы E ∈ R^L.d, где L — максимальная длина последовательности, а d — размерность векторов вложения. Каждая строка матрицы представляет вектор вложения для определенной позиции в последовательности.
Чтобы включить позиционные вложения во входное представление для заданной позиции pos в последовательности, вектор вложения слов x_pos и соответствующий позиционный вектор вложения p_pos добавляются поэлементно, в результате чего получается новый вектор z_pos:

z_pos будет выходом из шага 3.
Понимание архитектуры перед этапом 4 — входы и выходы
На этом этапе важно изучить различие между входными данными, которые отправляются на уровень кодировщика преобразователя, и входными данными, которые отправляются на уровень декодера. Давайте рассмотрим задачу машинного перевода, целью которой является перевод предложения с английского на французский с использованием модели Transformer.
Предложение на английском языке (ввод в кодировщик): «Я люблю изучать языки».
Французский перевод (целевая последовательность): «J’aime apprendre les langues».
INSIGHT: входные данные для кодировщика отправляются в виде пакета образцов. Образец можно рассматривать как абзац. Каждый образец состоит из токенов (или слов). Пакет устанавливается на размер выборки 64 (например), и каждая выборка заранее определена, чтобы иметь одинаковую длину токенов.
Если абзац короче длины выборки, он заполняется пустыми токенами, чтобы компенсировать длину. Если абзац длиннее, то он разбивается на несколько образцов.
Во время обучения целевая последовательность используется в качестве входных данных для декодера, но смещается на одну позицию. Мы также добавляем в целевую последовательность специальные маркеры начала последовательности (SOS) и конца последовательности (EOS).
Целевой ввод в декодер (сдвинутый): [SOS] J’aime apprendre les langues. [EOS]
Теперь давайте посмотрим, как декодер обрабатывает этот ввод во время обучения:
- Декодер получает сдвинутую целевую последовательность в качестве входных данных вместе с выходными данными кодировщика (которые представляют собой английское предложение).
- Декодер генерирует распределение вероятностей по французскому словарю для каждой позиции в выходной последовательности. Эти распределения представляют собой прогноз модели для следующего токена в последовательности в каждой позиции.
- Фактическая выходная последовательность, включая токен EOS, используется для расчета потерь: «J’aime apprendre les langues. [ЭОС]”
Предположим, что прогнозируемая выходная последовательность модели после обучения такова: «J’aime apprendre les langues».
Во время вывода при переводе нового английского предложения декодер начинает с токена SOS и генерирует выходную последовательность по одному токену за раз на основе предыдущих токенов и выходных данных кодировщика.
Например, давайте переведем новое предложение:
Английское предложение (ввод в кодировщик): «Ей нравится изучать историю».
Декодер начинает с токена SOS и шаг за шагом генерирует французский перевод:
- Ввод: [SOS]
- Выход: «Эль»
- Ввод: [SOS] «Эль».
- Вывод: «Айме»
- Ввод: [SOS] «Эль» «Эйм»
- Вывод: «étudier»
- Ввод: [SOS] «Elle» «aime» «étudier»
- Выход: «История»
- Ввод: [SOS] «Elle» «aime» «étudier» «l’histoire»
- Выход: [ЭОС]
Окончательный сгенерированный французский перевод: «Elle aime étudier l’histoire».
Шаг 4 — Матрица Q K V в кодировщике
Этот шаг имеет решающее значение для общего понимания. Каждый входной токен разветвляется на Запрос, Ключ и Значение или векторы Q, K и V путем умножения одного и того же токена на три разные матрицы весов. Первоначально вся весовая матрица инициируется случайным образом.
ПОНИМАНИЕ: мы поддерживаем Wq, Wk, Wv как 3 отдельные матрицы весов, которые представляют собой изученные параметры по всему корпусу обучения, оптимизированные с использованием оптимизации обратного распространения ошибки и градиентного спуска. Матрица весов обновляется только в конце каждой партии. Каждый токен X умножается на весовую матрицу Wq, Wk, Wv, чтобы получить векторы Q, K, V.

Матрица весов для Wq,Wk,иWv не обязательно должна быть тот же размер. У вас может быть меньшее значение для Wq и Wk и большее значение для Wv.
Во время каждой обучающей итерации модель берет набор входных последовательностей и выполняет прямой проход через слои преобразователя, что включает в себя вычисление показателей собственного внимания с использованием Q, K и V, за которыми следуют сетевые уровни прямой связи. Затем выходные данные модели сравниваются с метками истинности с использованием функции потерь и градиентов потерь по отношению ко всем параметрам модели, включая Q, K и V вычисляются с использованием обратного распространения ошибки.
Поскольку входные вложения зависят от конкретной входной последовательности, Q, K и V, полученные из этих вложений, также будут уникальными для каждого образца. Однако Wq, Wk и Wv матрицы весов являются общими для всех выборок, что позволяет модели обобщать различные входные последовательности.
Другими словами, Q, K и V сохраняются только на уровне образца и уникальны для каждого образца в партии (но Wq, Wk и Wv будут для всего корпуса).
Но зачем это нужно? Чего мы добиваемся, создавая Q, K или V векторы?
Нам нужно освежить немного математики, чтобы понять значение этого. Давайте подытожим наше понимание скалярных произведений двух векторов.

- Геометрическая интерпретация: скалярное произведение двух векторов a и b равно величине a, умноженное на величину b, умноженную на косинус угла между ними. Это означает, что скалярное произведение измеряет степень выравнивания между двумя векторами. Если векторы параллельны, скалярное произведение положительно и равно произведению их величин; если они антипараллельны, скалярное произведение отрицательно и равно отрицательному значению их произведения; если они перпендикулярны, скалярное произведение равно нулю.
- Интерпретация проекции: скалярное произведение двух векторов a и b равно длине проекции a на b, умноженное на величину b. Это означает, что скалярный продукт измеряет компонент a, параллельный b. Если a и b являются единичными векторами (т. е. векторами длины 1), скалярное произведение равно косинус угла между ними, который представляет степень подобия между двумя векторами.
- Алгебраическая интерпретация: скалярное произведение двух векторов a и b равно сумме произведений их соответствующие компоненты. Это означает, что скалярное произведение измеряет, насколько два вектора «перекрываются» в каждом измерении. Если векторы имеют положительные компоненты в одних и тех же измерениях, скалярное произведение положительно; если они имеют отрицательные компоненты в тех же измерениях, скалярное произведение отрицательно; если они имеют противоположные знаки или нулевые компоненты в любом измерении, скалярный продукт равен нулю.
Итак, теперь представьте, что каждое слово представляет собой вектор с плавающей запятой размером 512 в качестве его измерений (вложение входных данных в 512-мерное векторное пространство). Это означает, что вам нужна весовая матрица размером 512 x M, чтобы выполнять матричное умножение. Допустим, размер М равен 64.
Итак, у нас есть X (1 x 512) и Wq (512 x 64). результирующий вектор Q будет иметь размер 1 x 64.
Теперь у вас есть фиксированный вектор X размером 512 из входного пространства встраивания и изначально матрица случайных весов Wq . Когда вы умножаете вектор на матрицу, вы эффективно находите скалярное произведение Xс каждым столбцом Wq (Обратите внимание, что Wq относится ко всему корпусу).
Чтобы визуализировать это, подумайте о множестве небольших векторов, которые вы настраиваете в Wq и пытаетесь усилить, аннулировать или свести на нет фиксированный вектор, чтобы найти лучшее положение для X из семантического пространства распределения в пространство более низкого измерения, курируемое Attention.
Ключевым моментом является то, что, поскольку Wq является изученным параметром, вы просите нейронную сеть найти оптимальный вектор в каждом столбце весовой матрицы, который при умножении заданным словом X даст вам правильный запрос Q, такой что Q сохраняет сущность своих 512 многомерных контекстов в 64-мерном нижнем пространстве, которое заново изучается с использованием нижестоящего механизма внимания.
ИНСАЙТ: По сути, мы сжимаем размерность с 512 до 64-мерного пространства и дополнительно «перестраиваем» слова на основе нижестоящего механизма внимания, полученного с помощью обратного распространения. Мы переходим от Распределительного Семантического Пространства к пространству, которое точно контролируется посредством механизма Внимания во время этой трансформации.
Также обратите внимание, что у нас будет несколько Wq, Wk, Wv в слоях глубокого обучения (и разных головках Attention), а не одна. Комбинация всех этих низкоразмерных весовых матриц вместе представляет разные подпространства. Вы можете визуализировать Wq как набор векторов на нескольких слоях следующим образом:

Каждую строку на приведенной выше диаграмме можно рассматривать как весовую матрицу Wq из одного слоя. Несколько строк представляют Wq, сложенные в несколько слоев. Итак, представьте себе 64 столбца, каждый из которых содержит 512-мерный вектор. Каждый из этих векторов будет тщательно сформирован, чтобы указывать на 512-мерное пространство с помощью оптимизации градиента, чтобы представить контекст всего корпуса!
Шаг 5 — Оценка
На этом шаге мы умножаем вектор запроса меньшего размера Q на транспонирование «каждого» K ( набор ключевых векторов) в выборке. Это служит цели вычисления оценок, которые измеряют сходство между запросом и каждым ключом.

В частности, когда мы вычисляем показатель внимания между вектором запроса Q и транспонированием каждого ключевого вектора K, мы устанавливаем коллективные веса каждого запроса со всеми ключами.

Умножение Q на каждый K гарантирует, что мы вычислим взвешенную оценку для каждого ключа, что необходимо для получения весов. и взвешенная сумма Ценностей. Без этого шага мы не смогли бы вычислить показатели внимания, и механизм внимания не работал бы.
Итак, почему мы это делаем? Помните, что Q представляет собой низкоразмерный индекс для входного встраивания слова из 512-мерного пространства в 64-мерное. Кроме того, помните, что Q и K были созданы из одного и того же фиксированного вложения ввода X путем умножения их на весовую матрицу Wq и Wk соответственно.
Поэтому, когда вы вычисляете скалярное произведение Q с каждым K, вы просите усилить, аннулировать или свести на нет числовое значение слова в предложении со всеми другими словами в данной выборке (включая его самого) в зависимости от контекста слова.
Слова семантически связаны друг с другом на основе их значения, а также близости слов в предложении. На высшем уровне семантическое значение можно представить следующим образом:
- Синонимы: прыжок/прыжок/прыжок/прыжок/отскок
- Антонимы: быстро/медленно
- Категории: Фрукты/бананы
- Коннотации: молодой или детский, страстный или непостоянный.
- Омофоны: Suite vs Sweet, Serial vs Cereal
- Омографы: слеза (капля) vs слеза (бумага)
- Омонимы: банк (река) vs банк (деньги)
Слова также различаются по значению в зависимости от использования следующим образом:
- Концептуальное значение: это относится к базовому или словарному определению слова, которое описывает категорию или понятие, которое представляет слово. Например, концептуальное значение слова «собака» — это одомашненное млекопитающее, которое обычно держат в качестве домашнего питомца или используют для охоты.
- Коннотативное значение: это относится к ассоциациям или эмоциям, которые слово может вызывать за пределами его концептуального значения. На коннотативное значение часто влияют культурные и личные факторы, и оно может варьироваться в зависимости от человека и контекста. Например, слово «собака» может иметь положительное значение для человека, любящего животных, и отрицательное значение для человека, которого укусила собака.
- Коллокативное значение: это относится к образцам слов, которые обычно встречаются вместе с данным словом, что может влиять на значение слова в контексте. Например, слово «крепкий» может иметь разные собирательные значения в зависимости от слов, которые его сопровождают, например, «крепкий кофе» или «сильный ветер».
- Аффективное значение: это относится к эмоциональным или поведенческим коннотациям слова, которые могут быть положительными, отрицательными или нейтральными. На аффективное значение могут влиять тон голоса говорящего, язык тела и другие контекстуальные факторы. Например, слово «любовь» может иметь положительное аффективное значение, а слово «ненависть» может иметь отрицательное аффективное значение.
- Социальное значение: это относится к социальным и культурным ассоциациям слова, которые могут отражать социальные нормы, ценности и динамику власти. На социальное значение могут влиять такие факторы, как возраст, пол, этническая принадлежность и социальный класс. Например, слово «босс» может иметь разное социальное значение в зависимости от отношения говорящего к рассматриваемому человеку.
- Отраженное значение: это относится к ассоциациям или значениям, которые слово может иметь на основе его использования в конкретном контексте, даже если эти ассоциации не являются частью его концептуального значения. На отраженный смысл могут влиять намерения говорящего, ожидания аудитории и более широкий культурный и исторический контекст. Например, слово «стена» может иметь значения, связанные с разделением, защитой или исключением, в зависимости от контекста.
- Тематическое значение: это относится к основным или неявным темам или сообщениям, которые передаются с помощью языка. На тематическое значение могут влиять такие факторы, как жанр, структура дискурса и условности повествования. Например, новостная статья о политическом протесте может иметь тематическое значение, связанное с властью, сопротивлением и социальными изменениями.
Хотя дистрибутивная семантика могла бы уловить значительную часть отношений между словами на основе их совместного появления, она никогда не могла бы отдать должное всем семантическим отношениям и различным значениям, которые могло иметь слово.
Скалярное произведение Q и каждого K — лучший способ исправить это не только потому, что оно усиливает, аннулирует или сводит на нет информационный контент, представленный встраиванием, НО также потому, что Wq и Wk чрезвычайно динамичны и — это изученные параметры по всему корпусу с весами внимания.
ПОНИМАНИЕ. Слова, расположенные напротив в пространстве для встраивания, будут отрицать контекст друг друга. Ортогональные слова будут аннулировать контекст друг друга, а слова, похожие по контексту, будут усиливать друг друга.
Шаг 6 — Многоголовое внимание
Наконец, мы здесь. Теперь давайте обратим внимание на то, как внимание помогает улавливать семантические отношения и различающиеся значения слова в зависимости от контекста ситуации, а также влияние слов в предложениях, находящихся далеко друг от друга.
Интерпретация использования «Внимания» в «Трансформерах» может быть сложной, поскольку механизм имеет множество вариаций и нюансов. Однако в целом внимание в Transformers направлено на то, чтобы позволить модели выборочно обращать внимание на разные части входной последовательности в зависимости от текущего контекста и поставленной задачи.
Это может помочь модели лучше фиксировать долговременные зависимости и сложные взаимосвязи между различными частями последовательности, а также давать более точные и информативные выходные данные.
Объем внимания находится на уровне выборки. Это очень важно понять. В отличие от Wq, Wk,и Wv,, которые имеют глобальную область действия для всего корпуса, механизм внимания работает на уровне выборки в каждой партии.
Мы вычисляем оценки внимания между парами токенов во входной последовательности. Каждый образец имеет свою собственную матрицу внимания, которая специфична для отношений между маркерами во входной последовательности этого образца. Будет Nматрица внимания (если это внимание одной головы) для N образцов в пакете. Обратите внимание, что матрица внимания сбрасывается после каждой партии.
Теперь давайте посмотрим, как рассчитывается внимание:

Мы уже обсуждали, как получить скалярное произведение каждого Q на каждый K (транспонирование), и почему для этого. Внимание, которое мы используем, называется масштабируемым вниманием к себе. Давайте поймем, почему мы масштабируем его с помощью sqrt размерности вектора ключа.
Когда вы берете скалярное произведение Q и K, величина скалярного произведения может варьироваться в зависимости от размерность векторов. В частности, по мере увеличения размерности скалярное произведение имеет тенденцию к увеличению, что может вызвать численную нестабильность и затруднить оптимизацию модели. Чтобы смягчить эту проблему, механизм Attention часто включает коэффициент масштабирования, который делит скалярное произведение на квадратный корень размерности.
В частности, масштабирование скалярного произведения на квадратный корень из размерности гарантирует, что среднее скалярное произведение остается приблизительно постоянным независимо от размерности. Это означает, что оценки внимания будут иметь одинаковые значения по разным параметрам, что сделает их более интерпретируемыми и удобными для сравнения.
Почему мы должны применять softmax?
- Функция Softmax гарантирует, что сумма весов внимания равна 1. Это означает, что вектор контекста представляет собой взвешенную сумму значений, где веса в сумме составляют 1. Это гарантирует, что модель обращает внимание на всю соответствующую информацию во входной последовательности, и снижает вес или игнорирует нерелевантную или зашумленную информацию.
- Функция Softmax создает распределение вероятностей по парам ключ-значение. Это позволяет модели изучить распределение важности для различных частей входной последовательности. Изучая распределение вероятностей, модель может фиксировать более сложные взаимосвязи и зависимости между различными частями входной последовательности.
- Функция Softmax является дифференцируемой, что упрощает вычисление градиентов во время обратного распространения. Это позволяет обучать модель с использованием методов оптимизации на основе градиента, таких как стохастический градиентный спуск (SGD).
- Функция Softmax — естественный выбор для моделирования вероятностных распределений. Используя функцию Softmax, мы можем интерпретировать веса внимания как вероятности выбора каждой пары ключ-значение.
Почему мы должны использовать скалярное произведение для вектора значений V?
- Умножение показателя внимания на вектор значений V гарантирует, что модель обращает внимание на наиболее важные части входной последовательности, а также снижает вес или игнорирует нерелевантную или зашумленную информацию. Вычисляя взвешенную сумму значений, модель также может научиться фиксировать сложные отношения и зависимости между различными частями входной последовательности.
Теперь давайте немного разберемся с многоголовым вниманием. Многоголовое внимание – это вариант механизма внимания, который включает разделение Q, K и V на несколько меньших векторов и вычисление оценок внимания и векторов контекста отдельно для каждого подмножества векторов. Результирующие векторы контекста затем объединяются и проходят через линейную проекцию для получения окончательного результата.
Основное преимущество многоголового внимания состоит в том, что оно позволяет модели параллельно и с разных точек зрения обращать внимание на различную информацию. Входная матрица разделена на столбцы для многоголового внимания, и каждое разделение отправляется в другую головку.

Таким образом, Xh1, Xh2, Xh3… Xhn будет разделением на основе количества решек, которые у вас будут на одном слое глубокой нейронной сети. Таким образом, теперь у вас будет меньшая весовая матрица на голову, но размер Q, K,иV не изменится. Таким образом, вычислительная стоимость мультиголовки аналогична одноголовке с полной размерностью.

Почему мы это делаем? ИМО, ответ лежит в математике. Вот мое мнение.
- Представьте, что ваш входной вектор X ортогонален столбцу Wq. В этом случае, когда вы возьмете скалярное произведение, ваш вектор запроса станет равным нулю! В этом случае вы, возможно, ничего не узнали о контексте или значении слов (это может быть сделано намеренно).
- Но вместо этого, если вы взяли столбчатый срез ортогональных векторов Xh1, Xh2… Xhn, то в этом срезе есть информация, которая может привести к ненулевому значению ( срез может быть не ортогонален), которые можно использовать для вычисления лучших показателей внимания.
- Вероятность того, что все N фрагменты будут ортогональными, феноменально ниже.
- При наличии одной головы внимания усреднение информационного подпространства препятствует возможности более глубокого изучения встраивания входных данных.
- Мультиголовное внимание позволяет модели совместно воспринимать информацию из разных подпространств представления в разных позициях.

Существуют также инженерные и эмпирические причины, почему это полезно.
- С мультиголовкой вы привлекаете больше внимания, чем с одинарной. Так что при мелком слое вы получите такое же количество голов внимания.
- 384 слоя, внимание с одной головкой эквивалентно 48 слоям, внимание с 8 головками. Просто меньшее количество слоев с большим количеством головок внимания работает так же эффективно, как большее количество слоев и одна головка внимания.
- Multi-head уменьшает количество слоев, сохраняя то же количество головок внимания. Меньшие слои приводят к более стабильной сети.
Результат каждой главы «Внимание» — это вектор контекста, представляющий собой сумму всех оценок внимания 𝜶 каждого токена.

Вектор контекста теперь содержит контекст всех токенов в выборке, готовой к отправке на передовой уровень канала. Вы объединяете векторы контекста со всех головок, чтобы сшить вместе вывод внимания для нескольких головок следующим образом:


Вот пример иллюстрации.

Последний шаг показывает суммирование всех оценок внимания в единый вектор контекста. Нет вот весовая матрица, которая используется для объединения всего контекста вместе, что также является параметром обучения. Вектор контекста подается в нейронную сеть Feed Foward.
Подводя итог архитектуре кодировщика.
- Кодер состоит из стека из N одинаковых слоев.
- Каждый слой имеет два подслоя. Первый представляет собой механизм самоконтроля с несколькими головками, а второй представляет собой простую, ориентированную на положение, полностью подключенную сеть прямой связи.
- Используется остаточное соединение вокруг двух подуровней с последующей нормализацией уровня.
- Результатом каждого подслоя является LayerNorm(x + Sublayer(x)), где Sublayer(x) — это функция, реализуемая самим подуровнем.
- Чтобы облегчить эти остаточные соединения, все подслои в модели и встраивающие слои производят выходные данные размерности dmodel = 512.
Общий обзор декодера
Сторона декодера имеет почти ту же архитектуру, что и сторона кодировщика, за исключением двух изменений.
- Замаскированный слой внимания.
- Импорт ключа и вектора значения со стороны энкодера.
Давайте сначала разберемся с входами и выходами декодера.

Входы в декодер:
- Целевая последовательность (смещенная): во время обучения целевая последовательность (например, переведенное предложение в задаче машинного перевода) предоставляется декодеру в качестве входных данных, но она сдвинута на одну позицию. Это означает, что декодер получает все токены в целевой последовательности, кроме последнего. Это делается для того, чтобы модель научилась предсказывать следующий токен в последовательности с учетом предыдущих токенов.
- Выход энкодера: скрытые состояния, созданные энкодером, которые представляют входную последовательность или, другими словами, векторы K и V. Это используется в механизме внимания кодер-декодер на уровнях декодера.
Выходы декодера:
- Декодер выводит распределение вероятностей по целевому словарю для каждой позиции в выходной последовательности. Помните, что целевой словарь для GPT3 – 50 257 токенов BPE. Таким образом, размер логита для вывода декодера также составляет 50 257 измерений. Эти распределения вероятностей представляют собой прогноз модели для следующего токена в последовательности в каждой позиции.
- Во время обучения предсказанные распределения вероятностей сравниваются с истинными целевыми последовательностями и вычисляется функция потерь (обычно кросс-энтропийных потерь). Эта потеря сводится к минимуму во время обучения, чтобы улучшить способность модели генерировать правильные выходные последовательности.
- Во время логического вывода (т. е. когда модель используется для генерации выходных последовательностей для новых входных данных) входом декодера являются ранее сгенерированные токены. Процесс начинается со специального токена начала последовательности, и на каждом этапе модель предсказывает следующий токен на основе предыдущих. Это можно сделать с помощью жадного декодирования, поиска луча или других стратегий декодирования для создания окончательной выходной последовательности.
Как во время обучения, так и во время логического вывода декодер представляет собой распределение вероятностей по целевому словарю (50 257) для каждой позиции в выходной последовательности. Эти распределения представляют собой логиты после прохождения финального линейного слоя и активации softmax в декодере.
Однако процесс выбора предсказанных токенов из этих распределений вероятностей отличается во время обучения и логического вывода.
Во время обучения модель прогнозирует распределения вероятностей для всех позиций в выходной последовательности одновременно, а функция потерь рассчитывается на основе разницы между прогнозами модели и истинными целевыми токенами. От модели явно не требуется производить прогнозирование одного токена для каждой позиции во время обучения, поскольку все распределение вероятностей используется для расчета потерь и обратного распространения.
Во время логического вывода модель генерирует выходную последовательность по одному маркеру за раз. На каждом шаге декодер предсказывает распределение вероятностей по целевому словарю для следующей позиции в выходной последовательности. Из этого распределения выбирается один токен в качестве прогноза для этой позиции с использованием такой стратегии декодирования, как:
- Жадное декодирование: выберите токен с наибольшей вероятностью.
- Поиск лучей. Поддерживайте фиксированное количество последовательностей-кандидатов (лучей) и расширяйте их на основе вероятностей токенов. Отсекайте менее вероятные лучи на каждом шаге и продолжайте с наиболее вероятными.
- Выборка из первых k или выборка из первых p: выборка токена из наиболее вероятных токенов из первых k или p, что вносит некоторую случайность в процесс декодирования.
Таким образом, в то время как выходные данные декодера остаются вероятностным распределением по целевому словарю как при обучении, так и при выводе, способ использования этих вероятностных распределений для создания окончательной выходной последовательности отличается, при этом во время вывода создаются прогнозы с одним токеном.
Чтобы лучше понять это, давайте рассмотрим задачу машинного перевода, целью которой является перевод предложения с английского на французский с использованием модели Transformer. Предположим, у нас есть следующее английское предложение в качестве входных данных:
Английское предложение (ввод в кодировщик): «Я люблю изучать языки».
Во время логического вывода декодер генерирует французский перевод по одной лексеме за раз. Мы продемонстрируем этот процесс, используя жадное декодирование, поиск по лучу и выборку по топ-k.
Жадное декодирование:
Декодер начинает с маркера начала последовательности (SOS) и шаг за шагом генерирует выходную последовательность.
- Ввод: [SOS]
- Выходные вероятности: [0,01, 0,03, 0,05, …, 0,4, …, 0,01] (предположим, что самая высокая вероятность, 0,4, соответствует «J’aime»). Опять же, размер этого логита будет 50 257.
- Выбранный токен: «J’aime»
- Ввод: [SOS] «J'aime»
- Выходные вероятности: [0,01, 0,02, 0,03, …, 0,5, …, 0,01] (предположим, что наивысшая вероятность, 0,5, соответствует «apprendre»)
- Выбранный токен: «apprendre»
Этот процесс продолжается до тех пор, пока не будет сгенерирован токен конца последовательности (EOS) или пока не будет достигнута максимальная выходная длина.
Поиск луча (предполагается, что размер луча = 2):
Декодер поддерживает две последовательности-кандидаты (лучи) на каждом шаге и расширяет их на основе вероятностей маркеров.
Шаг 1:
- Луч 1: [SOS] «J’aime» (вероятность: 0,4)
- Луч 2: [SOS] «Je» (вероятность: 0,3, предположим, что «Je» — второй наиболее вероятный токен)
- Шаг 2:
- Луч 1: [SOS] «J’aime» «apprendre» (кумулятивная вероятность: 0,4 * 0,5 = 0,2)
- Луч 2: [SOS] «Je» «обожаю» (кумулятивная вероятность: 0,3 * 0,4 = 0,12, предположим, что «обожаю» является наиболее вероятным токеном после «Je»)
Процесс продолжается с наиболее вероятными лучами до тех пор, пока не будет сгенерирован токен EOS или не будет достигнута максимальная выходная длина.
Выборка лучших k (предполагается, что k = 3):
Декодер выбирает токен из k наиболее вероятных токенов на каждом шаге, вводя случайность.
- Ввод: [SOS]
- Топ-3 вероятности выхода: [("J’aime", 0.4), ("Je", 0.3), ("J'adore", 0.2)]
- Образец токена: «J’aime» (выбирается случайным образом на основе их вероятностей)
- Ввод: [SOS] «J'aime»
- Топ-3 выходных вероятностей: [("apprendre", 0,5), ("étudier", 0,3), ("pratiquer", 0,1)]
- Выборочный токен: «étudier» (выбирается случайным образом на основе их вероятностей)
Процесс продолжается до тех пор, пока не будет сгенерирован токен EOS или не будет достигнута максимальная выходная длина.
В каждой из этих стратегий декодирования декодер генерирует выходные маркеры по одному на основе распределения вероятностей по целевому словарю.
Примечание. Размер логит-слоя в декодере зависит от размера целевого словаря. в случае GPT3 токенизация BPE уменьшает общий словарный запас до 50 275 токенов, и это размер логит-слоя.
Шаг 7 — Слой замаскированного внимания
Слой замаскированного внимания на стороне декодера работает, маскируя будущие позиции во входной последовательности.
Это делается для того, чтобы декодер не обращал внимания на будущие позиции, что позволило бы ему «обмануть» и предсказать следующее слово в последовательности. Маскировка выполняется путем установки веса внимания для будущих позиций на очень маленькое значение, например -1e9. Это эффективно препятствует тому, чтобы декодер обращался к этим позициям.
Слой замаскированного внимания важен по двум причинам.
- Во-первых, это предотвращает переобучение декодером обучающих данных. Если бы декодер мог следить за будущими позициями, он мог бы запоминать обучающие данные и повторять их во время тестирования. Это была бы не очень полезная модель.
- Во-вторых, замаскированный слой внимания помогает декодеру сосредоточиться на текущем контексте. Не позволяя декодеру следить за будущими позициями, замаскированный уровень внимания заставляет декодер сосредоточиться на словах, которые уже были сгенерированы. Это помогает декодеру генерировать более точный и плавный текст.
Как работает замаскированное внимание?
Предположим, у нас есть входная последовательность длины N, которая была закодирована в последовательность ключевых векторов Kс размерность d_k и последовательность векторов значений V с размерностью d_v. У нас также есть декодер, который генерирует выходную последовательность длиной M, где M обычно короче, чем Н. Декодер генерирует выходную последовательность по одной лексеме за раз, обращаясь к закодированной входной последовательности и ранее сгенерированным лексемам.
Во время декодирования нам нужно убедиться, что декодер обращает внимание только на ранее сгенерированные токены, а не на будущие токены, которые еще не были сгенерированы. Для этого мы используем матрицу маски с размерами (M, N), заполненную единицами и минус бесконечностью. Матрица маски используется для маскирования будущих позиций в оценках внимания путем установки их значений на отрицательную бесконечность.
ПРИМЕЧАНИЕ. Вы не можете использовать нули для обозначения маски, поскольку ноль считается информацией.
Вот изображение само-внимания, когда последовательность преобразования учится сама по себе (это не вариант использования перевода).

Слой замаскированного внимания можно определить математически следующим образом:

Где Q — вектор запроса текущего токена, K и Vимпортируются из Encoder.
На следующем рисунке вы можете заметить, как маска блокирует просмотр запроса вперед.

Шаг 8 — Сторона декодера Q с импортом K, V.
Хотя остальные уровни декодера точно такие же, как у кодировщика, важно понимать, что декодер не генерирует свои собственные векторы ключа или значения. Вместо этого он заимствует K и V со стороны кодировщика.

Механизм внимания декодера должен обращать внимание только на выходную последовательность кодировщика и ранее сгенерированные токены выходной последовательности. Поэтому декодер использует одни и те же векторы K и V, сгенерированные кодировщиком для всех токенов в выходных данных. последовательность. Это отличается от кодировщика, который создает уникальный набор векторов K и V для каждого маркера в последовательность ввода.
Совместно используя векторы K и V для всех токенов в выходной последовательности, модель Transformer сокращает объем вычислений. стоимость механизма внимания и позволяет быстрее обучать и делать выводы.
Кроме того, совместное использование векторов K и V для всех токенов позволяет модели заниматься одними и теми же частями входную последовательность независимо от текущего выходного маркера, что может улучшить общую согласованность и согласованность выходной последовательности.
ПОНИМАНИЕ: Думайте о стороне декодера как о механизме поиска запроса. Декодер создает вектор запроса Q для каждой лексемы в образце, которую необходимо декодировать. Декодер оценивает запрос Q со стороны декодера по сравнению с ключами K от кодировщика. Это дает декодеру представление о наиболее полезном контексте, который следует учитывать из входной последовательности, подаваемой на кодировщик. После того, как веса подсчитаны вместе с ключом от кодировщика, декодер должен найти вектор значений, который служит наиболее семантически и контекстуально полезным значением для декодирования.
Конец игры
Остальные слои декодера точно такие же, как кодировщик. Вот некоторые важные вещи, которые нужно знать.
Непрерывный процесс обучения:
- Подготовка данных: Соберите параллельный корпус предложений на исходном и целевом языках (например, пары предложений на английском и французском языках). Разбейте предложения на слова или подслова, используя подходящий токенизатор. Добавьте специальные маркеры начала последовательности (SOS) и конца последовательности (EOS) к целевым предложениям.
- Пакетная обработка: организуйте токенизированные предложения в мини-пакеты для более эффективного обучения. Каждый мини-пакет содержит набор пар исходных и целевых предложений.
- Маскирование: создайте маски для входных последовательностей (исходной и целевой), чтобы модель не обращала внимание на маркеры заполнения.
- Вход энкодера: пропустите исходные предложения через энкодер Transformer. Кодер состоит из нескольких уровней с самостоятельным вниманием с несколькими головками, нормализацией уровня, сетями прямой связи по положению и нормализацией другого уровня. Кодер выводит последовательность скрытых состояний, представляющих входную последовательность.
- Вход декодера: пропустите целевые предложения (сдвинутые на одну позицию) через декодер преобразователя. Декодер также имеет несколько уровней, каждый с самостоятельным вниманием с несколькими головками, нормализацией уровня, вниманием кодера-декодера, нормализацией другого уровня, сетями с прямой связью по положению и нормализацией конечного уровня.
- Внимание кодера-декодера: во время шага внимания кодера-декодера в слоях декодера декодер обращает внимание на скрытые состояния из выходных данных кодера. Это помогает декодеру сосредоточиться на соответствующих частях исходного предложения при создании целевого предложения.
- Выходные вероятности: выходные данные последнего уровня декодера проходят через линейный уровень, за которым следует активация softmax, чтобы получить распределение вероятностей по целевому словарю для каждой позиции в выходной последовательности. Эти распределения представляют прогнозы модели для следующего токена в последовательности в каждой позиции.
- Расчет потерь: сравните прогнозируемую выходную последовательность с фактической целевой последовательностью (включая токен EOS), используя подходящую функцию потерь, такую как кросс-энтропийная потеря. Потеря измеряет разницу между предсказанными вероятностями и истинными вероятностями целевого токена.
- Обратное распространение: Вычислите градиенты потерь по отношению к параметрам модели (веса и смещения), используя алгоритм обратного распространения.
- Оптимизация: обновите параметры модели с помощью алгоритма оптимизации, такого как Adam или SGD, на основе вычисленных градиентов. На этом шаге настраиваются параметры модели, чтобы минимизировать потери.
- Повторите: повторите шаги, описанные выше, для нескольких эпох или до тех пор, пока не будет выполнен критерий остановки (например, потери сходятся или производительность модели на проверочном наборе перестанет улучшаться). Обрабатывайте разные мини-пакеты на каждой итерации.
- Проверка: периодически оценивайте производительность модели на отдельном наборе данных проверки, чтобы отслеживать ее способность к обобщению и предотвращать переоснащение. Настройте гиперпараметры или примените раннюю остановку в зависимости от производительности проверки.
Как преобразователь работает с входными и выходными последовательностями разной длины?
- В механизме внимания кодер-декодер запросы декодера (Q) используются для обработки ключей (K) и значения (V) из кодировщика.
- Этот процесс позволяет декодеру вычислять контекстно-зависимые взвешенные суммы векторов значений кодировщика на основе подобия между векторами запроса декодера и ключевыми векторами кодировщика. Механизм внимания не основан на предположении, что длина входной и выходной последовательностей одинакова. Он вычисляет оценки внимания и векторы контекста независимо для каждой позиции в выходной последовательности на основе взаимосвязей между запросами декодера и ключами кодировщика.
- Помните, что внимание рассчитывается для данного Q во всех парах [K, V]. Таким образом, декодер не заботится о размере входной или выходной последовательности, поскольку он вычисляет текущий Q для всех [K, V ] пар из кодировщика.
- Таким образом, несмотря на то, что количество ключей и значений в кодировщике и декодере может различаться из-за разной длины входных и выходных последовательностей, преобразователь все же может эффективно вычислять внимание кодера-декодера и генерировать соответствующие выходные последовательности.
Преимущества многоголового внимания к разным подпространствам:
- Адаптивность: механизм внимания может адаптироваться к конкретной структуре и зависимостям в каждой входной последовательности, позволяя модели изучать и представлять сложные отношения между токенами. Эта адаптивность позволяет модели лучше обрабатывать различные входные последовательности и обобщать невидимые данные.
- Представление с учетом контекста: разные матрицы внимания для каждого образца позволяют модели сосредоточиться на разных частях входной последовательности при создании векторов контекста. Это контекстно-зависимое представление позволяет модели лучше фиксировать значение каждого токена в контексте всей входной последовательности, улучшая качество вывода, особенно в таких задачах, как машинный перевод или суммирование текста.
- Параллелизм: при многоголовом внимании каждая головка внимания может одновременно изучать различные отношения между токенами, что приводит к множеству матриц внимания для каждой выборки. Этот параллелизм позволяет модели более эффективно фиксировать различные типы отношений (например, синтаксические, семантические или долгосрочные зависимости), повышая общую производительность.
- Интерпретируемость: различные матрицы внимания для каждой выборки могут обеспечить некоторый уровень интерпретируемости за счет визуализации весов внимания. Это может помочь в понимании того, как модель обращается к различным частям входной последовательности, и может раскрыть понимание изученных взаимосвязей между токенами.
Фух, вот и все, ребята. Этот блог исчерпал себя. Я углублюсь в математику в следующем наборе блогов. Удачной тренировки.